![]() Follow me on twitter @bradleyboehmke
Follow me on twitter @bradleyboehmke
![]() Follow me on twitter @bradleyboehmke
Follow me on twitter @bradleyboehmke
![]()
Bagging (bootstrap aggregating) regression trees is a technique that can turn a single tree model with high variance and poor predictive power into a fairly accurate prediction function. Unfortunately, bagging regression trees typically suffers from tree correlation, which reduces the overall performance of the model. Random forests are a modification of bagging that builds a large collection of de-correlated trees and have become a very popular “out-of-the-box” learning algorithm that enjoys good predictive performance. This tutorial will cover the fundamentals of random forests.
This tutorial serves as an introduction to the random forests. This tutorial will cover the following material:
ranger & h2o.This tutorial leverages the following packages. Some of these packages play a supporting role; however, we demonstrate how to implement random forests with several different packages and discuss the pros and cons to each.
library(rsample) # data splitting
library(randomForest) # basic implementation
library(ranger) # a faster implementation of randomForest
library(caret) # an aggregator package for performing many machine learning models
library(h2o) # an extremely fast java-based platform
To illustrate various regularization concepts we will use the Ames Housing data that has been included in the AmesHousing package.
# Create training (70%) and test (30%) sets for the AmesHousing::make_ames() data.
# Use set.seed for reproducibility
set.seed(123)
ames_split <- initial_split(AmesHousing::make_ames(), prop = .7)
ames_train <- training(ames_split)
ames_test <- testing(ames_split)
Random forests are built on the same fundamental principles as decision trees and bagging (check out this tutorial if you need a refresher on these techniques). Bagging trees introduces a random component in to the tree building process that reduces the variance of a single tree’s prediction and improves predictive performance. However, the trees in bagging are not completely independent of each other since all the original predictors are considered at every split of every tree. Rather, trees from different bootstrap samples typically have similar structure to each other (especially at the top of the tree) due to underlying relationships.
For example, if we create six decision trees with different bootstrapped samples of the Boston housing data, we see that the top of the trees all have a very similar structure. Although there are 15 predictor variables to split on, all six trees have both lstat and rm variables driving the first few splits.
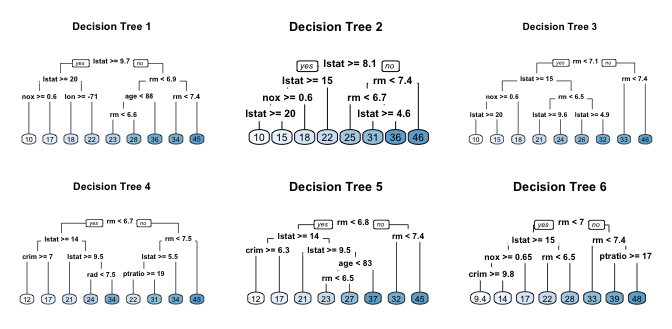
This characteristic is known as tree correlation and prevents bagging from optimally reducing variance of the predictive values. In order to reduce variance further, we need to minimize the amount of correlation between the trees. This can be achieved by injecting more randomness into the tree-growing process. Random forests achieve this in two ways:
The basic algorithm for a regression random forest can be generalized to the following:
1. Given training data set
2. Select number of trees to build (ntrees)
3. for i = 1 to ntrees do
4. | Generate a bootstrap sample of the original data
5. | Grow a regression tree to the bootstrapped data
6. | for each split do
7. | | Select m variables at random from all p variables
8. | | Pick the best variable/split-point among the m
9. | | Split the node into two child nodes
10. | end
11. | Use typical tree model stopping criteria to determine when a tree is complete (but do not prune)
12. end
Since the algorithm randomly selects a bootstrap sample to train on and predictors to use at each split, tree correlation will be lessened beyond bagged trees.
Similar to bagging, a natural benefit of the bootstrap resampling process is that random forests have an out-of-bag (OOB) sample that provides an efficient and reasonable approximation of the test error. This provides a built-in validation set without any extra work on your part, and you do not need to sacrifice any of your training data to use for validation. This makes identifying the number of trees required to stablize the error rate during tuning more efficient; however, as illustrated below some difference between the OOB error and test error are expected.

Furthermore, many packages do not keep track of which observations were part of the OOB sample for a given tree and which were not. If you are comparing multiple models to one-another, you’d want to score each on the same validation set to compare performance. Also, although technically it is possible to compute certain metrics such as root mean squared logarithmic error (RMSLE) on the OOB sample, it is not built in to all packages. So if you are looking to compare multiple models or use a slightly less traditional loss function you will likely want to still perform cross validation.
Advantages:
Disadvantages:
There are over 20 random forest packages in R.1 To demonstrate the basic implementation we illustrate the use of the randomForest package, the oldest and most well known implementation of the Random Forest algorithm in R. However, as your data set grows in size randomForest does not scale well (although you can parallelize with foreach). Moreover, to explore and compare a variety of tuning parameters we can also find more effective packages. Consequently, in the Tuning section we illustrate how to use the ranger and h2o packages for more efficient random forest modeling.
randomForest::randomForest can use the formula or separate x, y matrix notation for specifying our model. Below we apply the default randomForest model using the formulaic specification. The default random forest performs 500 trees and randomly selected predictor variables at each split. Averaging across all 500 trees provides an OOB ().
# for reproduciblity
set.seed(123)
# default RF model
m1 <- randomForest(
formula = Sale_Price ~ .,
data = ames_train
)
m1
##
## Call:
## randomForest(formula = Sale_Price ~ ., data = ames_train)
## Type of random forest: regression
## Number of trees: 500
## No. of variables tried at each split: 26
##
## Mean of squared residuals: 659550782
## % Var explained: 89.83
Plotting the model will illustrate the error rate as we average across more trees and shows that our error rate stabalizes with around 100 trees but continues to decrease slowly until around 300 or so trees.
plot(m1)

The plotted error rate above is based on the OOB sample error and can be accessed directly at m1$mse. Thus, we can find which number of trees providing the lowest error rate, which is 344 trees providing an average home sales price error of $25,673.
# number of trees with lowest MSE
which.min(m1$mse)
## [1] 344
# RMSE of this optimal random forest
sqrt(m1$mse[which.min(m1$mse)])
## [1] 25673.5
randomForest also allows us to use a validation set to measure predictive accuracy if we did not want to use the OOB samples. Here we split our training set further to create a training and validation set. We then supply the validation data in the xtest and ytest arguments.
# create training and validation data
set.seed(123)
valid_split <- initial_split(ames_train, .8)
# training data
ames_train_v2 <- analysis(valid_split)
# validation data
ames_valid <- assessment(valid_split)
x_test <- ames_valid[setdiff(names(ames_valid), "Sale_Price")]
y_test <- ames_valid$Sale_Price
rf_oob_comp <- randomForest(
formula = Sale_Price ~ .,
data = ames_train_v2,
xtest = x_test,
ytest = y_test
)
# extract OOB & validation errors
oob <- sqrt(rf_oob_comp$mse)
validation <- sqrt(rf_oob_comp$test$mse)
# compare error rates
tibble::tibble(
`Out of Bag Error` = oob,
`Test error` = validation,
ntrees = 1:rf_oob_comp$ntree
) %>%
gather(Metric, RMSE, -ntrees) %>%
ggplot(aes(ntrees, RMSE, color = Metric)) +
geom_line() +
scale_y_continuous(labels = scales::dollar) +
xlab("Number of trees")

Random forests are one of the best “out-of-the-box” machine learning algorithms. They typically perform remarkably well with very little tuning required. For example, as we saw above, we were able to get an RMSE of less than $30K without any tuning which is over a $6K reduction to the RMSE achieved with a fully-tuned bagging model and $4K reduction to to a fully-tuned elastic net model. However, we can still seek improvement by tuning our random forest model.
Random forests are fairly easy to tune since there are only a handful of tuning parameters. Typically, the primary concern when starting out is tuning the number of candidate variables to select from at each split. However, there are a few additional hyperparameters that we should be aware of. Although the argument names may differ across packages, these hyperparameters should be present:
ntree: number of trees. We want enough trees to stabalize the error but using too many trees is unncessarily inefficient, especially when using large data sets.mtry: the number of variables to randomly sample as candidates at each split. When mtry the model equates to bagging. When mtry the split variable is completely random, so all variables get a chance but can lead to overly biased results. A common suggestion is to start with 5 values evenly spaced across the range from 2 to p.sampsize: the number of samples to train on. The default value is 63.25% of the training set since this is the expected value of unique observations in the bootstrap sample. Lower sample sizes can reduce the training time but may introduce more bias than necessary. Increasing the sample size can increase performance but at the risk of overfitting because it introduces more variance. Typically, when tuning this parameter we stay near the 60-80% range.nodesize: minimum number of samples within the terminal nodes. Controls the complexity of the trees. Smaller node size allows for deeper, more complex trees and smaller node results in shallower trees. This is another bias-variance tradeoff where deeper trees introduce more variance (risk of overfitting) and shallower trees introduce more bias (risk of not fully capturing unique patters and relatonships in the data).maxnodes: maximum number of terminal nodes. Another way to control the complexity of the trees. More nodes equates to deeper, more complex trees and less nodes result in shallower trees.If we are interested with just starting out and tuning the mtry parameter we can use randomForest::tuneRF for a quick and easy tuning assessment. tuneRf will start at a value of mtry that you supply and increase by a certain step factor until the OOB error stops improving be a specified amount. For example, the below starts with mtry = 5 and increases by a factor of 1.5 until the OOB error stops improving by 1%. Note that tuneRF requires a separate x y specification. We see that the optimal mtry value in this sequence is very close to the default mtry value of .
# names of features
features <- setdiff(names(ames_train), "Sale_Price")
set.seed(123)
m2 <- tuneRF(
x = ames_train[features],
y = ames_train$Sale_Price,
ntreeTry = 500,
mtryStart = 5,
stepFactor = 1.5,
improve = 0.01,
trace = FALSE # to not show real-time progress
)
## -0.02973818 0.01
## 0.0607281 0.01
## 0.01912042 0.01
## 0.02776082 0.01
## 0.01091969 0.01
## -0.01001876 0.01

To perform a larger grid search across several hyperparameters we’ll need to create a grid and loop through each hyperparameter combination and evaluate the model. Unfortunately, this is where randomForest becomes quite inefficient since it does not scale well. Instead, we can use ranger which is a C++ implementation of Brieman’s random forest algorithm and, as the following illustrates, is over 6 times faster than randomForest.
# randomForest speed
system.time(
ames_randomForest <- randomForest(
formula = Sale_Price ~ .,
data = ames_train,
ntree = 500,
mtry = floor(length(features) / 3)
)
)
## user system elapsed
## 55.371 0.590 57.364
# ranger speed
system.time(
ames_ranger <- ranger(
formula = Sale_Price ~ .,
data = ames_train,
num.trees = 500,
mtry = floor(length(features) / 3)
)
)
## user system elapsed
## 9.267 0.215 2.997
To perform the grid search, first we want to construct our grid of hyperparameters. We’re going to search across 96 different models with varying mtry, minimum node size, and sample size.
# hyperparameter grid search
hyper_grid <- expand.grid(
mtry = seq(20, 30, by = 2),
node_size = seq(3, 9, by = 2),
sampe_size = c(.55, .632, .70, .80),
OOB_RMSE = 0
)
# total number of combinations
nrow(hyper_grid)
## [1] 96
We loop through each hyperparameter combination and apply 500 trees since our previous examples illustrated that 500 was plenty to achieve a stable error rate. Also note that we set the random number generator seed. This allows us to consistently sample the same observations for each sample size and make it more clear the impact that each change makes. Our OOB RMSE ranges between ~26,000-27,000. Our top 10 performing models all have RMSE values right around 26,000 and the results show that models with slighly larger sample sizes (70-80%) and deeper trees (3-5 observations in an terminal node) perform best. We get a full range of mtry values showing up in our top 10 so is does not look like that is over influential.
for(i in 1:nrow(hyper_grid)) {
# train model
model <- ranger(
formula = Sale_Price ~ .,
data = ames_train,
num.trees = 500,
mtry = hyper_grid$mtry[i],
min.node.size = hyper_grid$node_size[i],
sample.fraction = hyper_grid$sampe_size[i],
seed = 123
)
# add OOB error to grid
hyper_grid$OOB_RMSE[i] <- sqrt(model$prediction.error)
}
hyper_grid %>%
dplyr::arrange(OOB_RMSE) %>%
head(10)
## mtry node_size sampe_size OOB_RMSE
## 1 20 5 0.8 25918.20
## 2 20 3 0.8 25963.96
## 3 28 3 0.8 25997.78
## 4 22 5 0.8 26041.05
## 5 22 3 0.8 26050.63
## 6 20 7 0.8 26061.72
## 7 26 3 0.8 26069.40
## 8 28 5 0.8 26069.83
## 9 26 7 0.8 26075.71
## 10 20 9 0.8 26091.08
Although, random forests typically perform quite well with categorical variables in their original columnar form, it is worth checking to see if alternative encodings can increase performance. For example, the following one-hot encodes our categorical variables which produces 353 predictor variables versus the 80 we were using above. We adjust our mtry parameter to search from 50-200 random predictor variables at each split and re-perform our grid search. The results suggest that one-hot encoding does not improve performance.
# one-hot encode our categorical variables
one_hot <- dummyVars(~ ., ames_train, fullRank = FALSE)
ames_train_hot <- predict(one_hot, ames_train) %>% as.data.frame()
# make ranger compatible names
names(ames_train_hot) <- make.names(names(ames_train_hot), allow_ = FALSE)
# hyperparameter grid search --> same as above but with increased mtry values
hyper_grid_2 <- expand.grid(
mtry = seq(50, 200, by = 25),
node_size = seq(3, 9, by = 2),
sampe_size = c(.55, .632, .70, .80),
OOB_RMSE = 0
)
# perform grid search
for(i in 1:nrow(hyper_grid_2)) {
# train model
model <- ranger(
formula = Sale.Price ~ .,
data = ames_train_hot,
num.trees = 500,
mtry = hyper_grid_2$mtry[i],
min.node.size = hyper_grid_2$node_size[i],
sample.fraction = hyper_grid_2$sampe_size[i],
seed = 123
)
# add OOB error to grid
hyper_grid_2$OOB_RMSE[i] <- sqrt(model$prediction.error)
}
hyper_grid_2 %>%
dplyr::arrange(OOB_RMSE) %>%
head(10)
## mtry node_size sampe_size OOB_RMSE
## 1 50 3 0.8 26981.17
## 2 75 3 0.8 27000.85
## 3 75 5 0.8 27040.55
## 4 75 7 0.8 27086.80
## 5 50 5 0.8 27113.23
## 6 125 3 0.8 27128.26
## 7 100 3 0.8 27131.08
## 8 125 5 0.8 27136.93
## 9 125 3 0.7 27155.03
## 10 200 3 0.8 27171.37
Currently, the best random forest model we have found retains columnar categorical variables and uses mtry = 24, terminal node size of 5 observations, and a sample size of 80%. Lets repeat this model to get a better expectation of our error rate. We see that our expected error ranges between ~25,800-26,400 with a most likely just shy of 26,200.
OOB_RMSE <- vector(mode = "numeric", length = 100)
for(i in seq_along(OOB_RMSE)) {
optimal_ranger <- ranger(
formula = Sale_Price ~ .,
data = ames_train,
num.trees = 500,
mtry = 24,
min.node.size = 5,
sample.fraction = .8,
importance = 'impurity'
)
OOB_RMSE[i] <- sqrt(optimal_ranger$prediction.error)
}
hist(OOB_RMSE, breaks = 20)

Furthermore, you may have noticed we set importance = 'impurity' in the above modeling, which allows us to assess variable importance. Variable importance is measured by recording the decrease in MSE each time a variable is used as a node split in a tree. The remaining error left in predictive accuracy after a node split is known as node impurity and a variable that reduces this impurity is considered more imporant than those variables that do not. Consequently, we accumulate the reduction in MSE for each variable across all the trees and the variable with the greatest accumulated impact is considered the more important, or impactful. We see that Overall_Qual has the greatest impact in reducing MSE across our trees, followed by Gr_Liv_Area, Garage_Cars, etc.
optimal_ranger$variable.importance %>%
tidy() %>%
dplyr::arrange(desc(x)) %>%
dplyr::top_n(25) %>%
ggplot(aes(reorder(names, x), x)) +
geom_col() +
coord_flip() +
ggtitle("Top 25 important variables")

If you ran the grid search code above you probably noticed the code took a while to run. Although ranger is computationally efficient, as the grid search space expands, the manual for loop process becomes less efficient. h2o is a powerful and efficient java-based interface that provides parallel distributed algorithms. Moreover, h2o allows for different optimal search paths in our grid search. This allows us to be more efficient in tuning our models. Here, I demonstrate how to tune a random forest model with h2o. Lets go ahead and start up h2o:
# start up h2o (I turn off progress bars when creating reports/tutorials)
h2o.no_progress()
h2o.init(max_mem_size = "5g")
## Connection successful!
##
## R is connected to the H2O cluster:
## H2O cluster uptime: 22 hours 14 minutes
## H2O cluster timezone: America/New_York
## H2O data parsing timezone: UTC
## H2O cluster version: 3.18.0.4
## H2O cluster version age: 1 month and 29 days
## H2O cluster name: H2O_started_from_R_bradboehmke_edi332
## H2O cluster total nodes: 1
## H2O cluster total memory: 0.33 GB
## H2O cluster total cores: 4
## H2O cluster allowed cores: 4
## H2O cluster healthy: TRUE
## H2O Connection ip: localhost
## H2O Connection port: 54321
## H2O Connection proxy: NA
## H2O Internal Security: FALSE
## H2O API Extensions: XGBoost, Algos, AutoML, Core V3, Core V4
## R Version: R version 3.4.4 (2018-03-15)
First, we can try a comprehensive (full cartesian) grid search, which means we will examine every combination of hyperparameter settings that we specify in hyper_grid.h2o. Here, we search across 96 models but since we perform a full cartesian search this process is not any faster than that which we did above. However, note that the best performing model has an OOB RMSE of 24504 (), which is lower than what we achieved previously. This is because some of the default settings regarding minimum node size, tree depth, etc. are more “generous” than ranger and randomForest (i.e. h2o has a default minimum node size of one whereas ranger and randomForest default settings are 5).
# create feature names
y <- "Sale_Price"
x <- setdiff(names(ames_train), y)
# turn training set into h2o object
train.h2o <- as.h2o(ames_train)
# hyperparameter grid
hyper_grid.h2o <- list(
ntrees = seq(200, 500, by = 100),
mtries = seq(20, 30, by = 2),
sample_rate = c(.55, .632, .70, .80)
)
# build grid search
grid <- h2o.grid(
algorithm = "randomForest",
grid_id = "rf_grid",
x = x,
y = y,
training_frame = train.h2o,
hyper_params = hyper_grid.h2o,
search_criteria = list(strategy = "Cartesian")
)
# collect the results and sort by our model performance metric of choice
grid_perf <- h2o.getGrid(
grid_id = "rf_grid",
sort_by = "mse",
decreasing = FALSE
)
print(grid_perf)
## H2O Grid Details
## ================
##
## Grid ID: rf_grid
## Used hyper parameters:
## - mtries
## - ntrees
## - sample_rate
## Number of models: 96
## Number of failed models: 0
##
## Hyper-Parameter Search Summary: ordered by increasing mse
## mtries ntrees sample_rate model_ids mse
## 1 20 300 0.8 rf_grid_model_78 6.004646344499717E8
## 2 28 300 0.8 rf_grid_model_82 6.061414247664825E8
## 3 26 500 0.8 rf_grid_model_93 6.0854677191578E8
## 4 30 400 0.7 rf_grid_model_65 6.119181849949034E8
## 5 24 500 0.8 rf_grid_model_92 6.127942641620891E8
##
## ---
## mtries ntrees sample_rate model_ids mse
## 91 22 200 0.55 rf_grid_model_1 6.66343543334637E8
## 92 20 400 0.55 rf_grid_model_12 6.731468505798283E8
## 93 20 300 0.55 rf_grid_model_6 6.743586125314143E8
## 94 28 200 0.55 rf_grid_model_4 6.75350240196085E8
## 95 28 400 0.55 rf_grid_model_16 6.784587234660429E8
## 96 30 200 0.55 rf_grid_model_5 6.90411858695978E8
Because of the combinatorial explosion, each additional hyperparameter that gets added to our grid search has a huge effect on the time to complete. Consequently, h2o provides an additional grid search path called “RandomDiscrete”, which will jump from one random combination to another and stop once a certain level of improvement has been made, certain amount of time has been exceeded, or a certain amount of models have been ran (or a combination of these have been met). Although using a random discrete search path will likely not find the optimal model, it typically does a good job of finding a very good model.
For example, the following code searches a large grid search of 2,025 hyperparameter combinations. We create a random grid search that will stop if none of the last 10 models have managed to have a 0.5% improvement in MSE compared to the best model before that. If we continue to find improvements then I cut the grid search off after 600 seconds (30 minutes). Our grid search assessed 190 models and the best model (max_depth = 30, min_rows = 1, mtries = 25, nbins = 30, ntrees = 200, sample_rate = .8) achived an RMSE of 24686 ().
# hyperparameter grid
hyper_grid.h2o <- list(
ntrees = seq(200, 500, by = 150),
mtries = seq(15, 35, by = 10),
max_depth = seq(20, 40, by = 5),
min_rows = seq(1, 5, by = 2),
nbins = seq(10, 30, by = 5),
sample_rate = c(.55, .632, .75)
)
# random grid search criteria
search_criteria <- list(
strategy = "RandomDiscrete",
stopping_metric = "mse",
stopping_tolerance = 0.005,
stopping_rounds = 10,
max_runtime_secs = 30*60
)
# build grid search
random_grid <- h2o.grid(
algorithm = "randomForest",
grid_id = "rf_grid2",
x = x,
y = y,
training_frame = train.h2o,
hyper_params = hyper_grid.h2o,
search_criteria = search_criteria
)
# collect the results and sort by our model performance metric of choice
grid_perf2 <- h2o.getGrid(
grid_id = "rf_grid2",
sort_by = "mse",
decreasing = FALSE
)
print(grid_perf2)
## H2O Grid Details
## ================
##
## Grid ID: rf_grid2
## Used hyper parameters:
## - max_depth
## - min_rows
## - mtries
## - nbins
## - ntrees
## - sample_rate
## Number of models: 190
## Number of failed models: 0
##
## Hyper-Parameter Search Summary: ordered by increasing mse
## max_depth min_rows mtries nbins ntrees sample_rate model_ids
## 1 30 1.0 25 30 200 0.8 rf_grid2_model_114
## 2 30 1.0 30 30 400 0.8 rf_grid2_model_60
## 3 25 1.0 20 25 200 0.8 rf_grid2_model_62
## 4 20 1.0 20 15 400 0.8 rf_grid2_model_48
## 5 20 1.0 15 15 350 0.75 rf_grid2_model_149
## mse
## 1 6.09386451519276E8
## 2 6.141013192008269E8
## 3 6.143676001174936E8
## 4 6.181798579219993E8
## 5 6.182797259475644E8
##
## ---
## max_depth min_rows mtries nbins ntrees sample_rate model_ids
## 185 30 5.0 30 15 500 0.55 rf_grid2_model_126
## 186 35 5.0 15 10 300 0.55 rf_grid2_model_84
## 187 25 5.0 15 20 200 0.55 rf_grid2_model_20
## 188 35 5.0 15 10 200 0.55 rf_grid2_model_184
## 189 40 1.0 15 20 400 0.55 rf_grid2_model_127
## 190 30 1.0 25 20 500 0.632 rf_grid2_model_189
## mse
## 185 7.474602079646143E8
## 186 7.530174943920757E8
## 187 7.591548840980767E8
## 188 7.721963479865576E8
## 189 1.0642428537243171E9
## 190 1.4912496290688899E9
Once we’ve identifed the best model we can get that model and apply it to our hold-out test set to compute our final test error. We see that we’ve been able to reduce our RMSE to near $23,000, which is a $10K reduction compared to elastic nets and bagging.
# Grab the model_id for the top model, chosen by validation error
best_model_id <- grid_perf2@model_ids[[1]]
best_model <- h2o.getModel(best_model_id)
# Now let’s evaluate the model performance on a test set
ames_test.h2o <- as.h2o(ames_test)
best_model_perf <- h2o.performance(model = best_model, newdata = ames_test.h2o)
# RMSE of best model
h2o.mse(best_model_perf) %>% sqrt()
## [1] 23104.67
Once we’ve identified our preferred model we can use the traditional predict function to make predictions on a new data set. We can use this for all our model types (randomForest, ranger, and h2o); although the outputs differ slightly. Also, not that the new data for the h2o model needs to be an h2o object.
# randomForest
pred_randomForest <- predict(ames_randomForest, ames_test)
head(pred_randomForest)
## 1 2 3 4 5 6
## 128266.7 153888.0 264044.2 379186.5 212915.1 210611.4
# ranger
pred_ranger <- predict(ames_ranger, ames_test)
head(pred_ranger$predictions)
## [1] 128440.6 154160.1 266428.5 389959.6 225927.0 214493.1
# h2o
pred_h2o <- predict(best_model, ames_test.h2o)
head(pred_h2o)
## predict
## 1 126903.1
## 2 154215.9
## 3 265242.9
## 4 381486.6
## 5 211334.3
## 6 202046.5
Random forests provide a very powerful out-of-the-box algorithm that often has great predictive accuracy. Because of their more simplistic tuning nature and the fact that they require very little, if any, feature pre-processing they are often one of the first go-to algorithms when facing a predictive modeling problem. To learn more I would start with the following resources listed in order of complexity:
See the Random Forest section in the Machine Learning Task View on CRAN and Erin LeDell’s useR! Machine Learning Tutorial for a non-comprehensive list. ↩