![]() Follow me on twitter @bradleyboehmke
Follow me on twitter @bradleyboehmke
![]() Follow me on twitter @bradleyboehmke
Follow me on twitter @bradleyboehmke
At first glance (and second, third,…) the regex syntax can appear quite confusing. This section will provide you with the basic foundation of regex syntax; however, realize that there is a plethora of resources available that will give you far more detailed, and advanced, knowledge of regex syntax. To read more about the specifications and technicalities of regex in R you can find help at help(regex) or help(regexp).
Metacharacters consist of non-alphanumeric symbols such as:
To match metacharacters in R you need to escape them with a double backslash “\\”. The following displays the general escape syntax for the most common metacharacters:
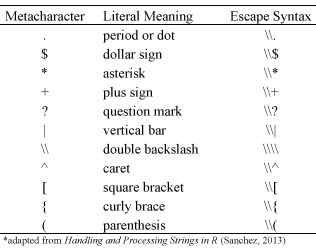
The following provides examples to show how to use the escape syntax to find and replace metacharacters. For information on the sub and gsub functions used in this example visit the main regex functions page.
# substitute $ with !
sub(pattern = "\\$", "\\!", "I love R$")
## [1] "I love R!"
# substitute ^ with carrot
sub(pattern = "\\^", "carrot", "My daughter has a ^ with almost every meal!")
## [1] "My daughter has a carrot with almost every meal!"
# substitute \\ with whitespace
gsub(pattern = "\\\\", " ", "I\\need\\space")
## [1] "I need space"
To match a sequence of characters we can apply short-hand notation which captures the fundamental types of sequences. The following displays the general syntax for these common sequences:

The following provides examples to show how to use the anchor syntax to find and replace sequences. For information on the gsub function used in this example visit the main regex functions page.
# substitute any digit with an underscore
gsub(pattern = "\\d", "_", "I'm working in RStudio v.0.99.484")
## [1] "I'm working in RStudio v._.__.___"
# substitute any non-digit with an underscore
gsub(pattern = "\\D", "_", "I'm working in RStudio v.0.99.484")
## [1] "_________________________0_99_484"
# substitute any whitespace with underscore
gsub(pattern = "\\s", "_", "I'm working in RStudio v.0.99.484")
## [1] "I'm_working_in_RStudio_v.0.99.484"
# substitute any wording with underscore
gsub(pattern = "\\w", "_", "I'm working in RStudio v.0.99.484")
## [1] "_'_ _______ __ _______ _._.__.___"
To match one of several characters in a specified set we can enclose the characters of concern with square brackets [ ]. In addition, to match any characters not in a specified character set we can include the caret ^ at the beginning of the set within the brackets. The following displays the general syntax for common character classes but these can be altered easily as shown in the examples that follow:

The following provides examples to show how to use the anchor syntax to match character classes. For information on the grep function used in this example visit the main regex functions page.
x <- c("RStudio", "v.0.99.484", "2015", "09-22-2015", "grep vs. grepl")
# find any strings with numeric values between 0-9
grep(pattern = "[0-9]", x, value = TRUE)
## [1] "v.0.99.484" "2015" "09-22-2015"
# find any strings with numeric values between 6-9
grep(pattern = "[6-9]", x, value = TRUE)
## [1] "v.0.99.484" "09-22-2015"
# find any strings with the character R or r
grep(pattern = "[Rr]", x, value = TRUE)
## [1] "RStudio" "grep vs. grepl"
# find any strings that have non-alphanumeric characters
grep(pattern = "[^0-9a-zA-Z]", x, value = TRUE)
## [1] "v.0.99.484" "09-22-2015" "grep vs. grepl"
Closely related to regex character classes are POSIX character classes which are expressed in double brackets [[ ]].

The following provides examples to show how to use the anchor syntax to match POSIX character classes. For information on the grep function used in this example visit the main regex functions page.
x <- "I like beer! #beer, @wheres_my_beer, I like R (v3.2.2) #rrrrrrr2015"
# remove space or tabs
gsub(pattern = "[[:blank:]]", replacement = "", x)
## [1] "Ilikebeer!#beer,@wheres_my_beer,IlikeR(v3.2.2)#rrrrrrr2015"
# replace punctuation with whitespace
gsub(pattern = "[[:punct:]]", replacement = " ", x)
## [1] "I like beer beer wheres my beer I like R v3 2 2 rrrrrrr2015"
# remove alphanumeric characters
gsub(pattern = "[[:alnum:]]", replacement = "", x)
## [1] " ! #, @__, (..) #"
When we want to match a certain number of characters that meet a certain criteria we can apply quantifiers to our pattern searches. The quantifiers we can use are:

The following provides examples to show how to use the quantifier syntax to match a certain number of characters patterns. For information on the grep function used in this example visit the main regex functions page. Note that state.name is a built in dataset within R that contains all the U.S. state names.
# match states that contain z
grep(pattern = "z+", state.name, value = TRUE)
## [1] "Arizona"
# match states with two s
grep(pattern = "s{2}", state.name, value = TRUE)
## [1] "Massachusetts" "Mississippi" "Missouri" "Tennessee"
# match states with one or two s
grep(pattern = "s{1,2}", state.name, value = TRUE)
## [1] "Alaska" "Arkansas" "Illinois" "Kansas"
## [5] "Louisiana" "Massachusetts" "Minnesota" "Mississippi"
## [9] "Missouri" "Nebraska" "New Hampshire" "New Jersey"
## [13] "Pennsylvania" "Rhode Island" "Tennessee" "Texas"
## [17] "Washington" "West Virginia" "Wisconsin"