![]() Follow me on twitter @bradleyboehmke
Follow me on twitter @bradleyboehmke
![]() Follow me on twitter @bradleyboehmke
Follow me on twitter @bradleyboehmke
Resampling methods are an indispensable tool in modern statistics. They involve repeatedly drawing samples from a training set and refitting a model of interest on each sample in order to obtain additional information about the fitted model. For example, in order to estimate the variability of a linear regression fit, we can repeatedly draw different samples from the training data, fit a linear regression to each new sample, and then examine the extent to which the resulting fits differ. Such an approach may allow us to obtain information that would not be available from fitting the model only once using the original training sample.
This tutorial serves as an introduction to sampling methods and covers1:
This tutorial primarily leverages the Auto data provided by the ISLR package. This is a data set that contains gas mileage, horsepower, and other information for 392 vehicles. We’ll also use tidyverse for some basic data manipulation and visualization. Most importantly, we’ll use the boot package to illustrate resampling methods.
# Packages
library(tidyverse) # data manipulation and visualization
library(boot) # resampling and bootstrapping
# Load data
(auto <- as_tibble(ISLR::Auto))
## # A tibble: 392 × 9
## mpg cylinders displacement horsepower weight acceleration year
## * <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 18 8 307 130 3504 12.0 70
## 2 15 8 350 165 3693 11.5 70
## 3 18 8 318 150 3436 11.0 70
## 4 16 8 304 150 3433 12.0 70
## 5 17 8 302 140 3449 10.5 70
## 6 15 8 429 198 4341 10.0 70
## 7 14 8 454 220 4354 9.0 70
## 8 14 8 440 215 4312 8.5 70
## 9 14 8 455 225 4425 10.0 70
## 10 15 8 390 190 3850 8.5 70
## # ... with 382 more rows, and 2 more variables: origin <dbl>, name <fctr>
Thus far, in our tutorials we have been using the validation or hold-out approach to estimate the prediction error of our predictive models. This involves randomly dividing the available set of observations into two parts, a training set and a testing set (aka validation set). Our statistical model is fit on the training set, and the fitted model is used to predict the responses for the observations in the validation set. The resulting validation set error rate (typically assessed using MSE in the case of a quantitative response) provides an estimate of the test error rate.
The validation set approach is conceptually simple and is easy to implement. But it has two potential drawbacks:
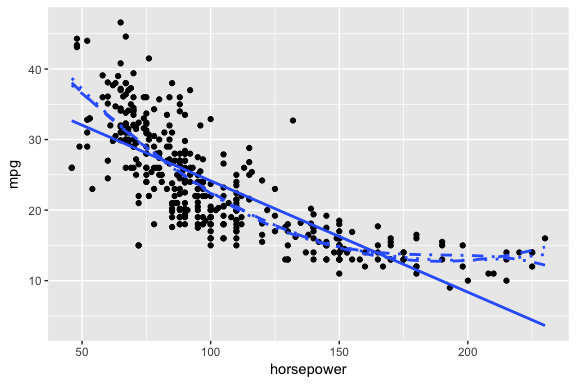
First, the estimate of the test error rate can be highly variable, depending on precisely which observations are included in the training set and which observations are included in the validation set. I will illustrate on our auto data set. Here we see that there is a relationship between mpg and horsepower and it doesn’t seem linear but we’re not sure which polynomial degree creates the best fit.
ggplot(auto, aes(horsepower, mpg)) +
geom_point() +
geom_smooth(method = "lm", se = FALSE) +
geom_smooth(method = "lm", formula = y ~ poly(x, 2), se = FALSE, linetype = 2) +
geom_smooth(method = "lm", formula = y ~ poly(x, 3), se = FALSE, linetype = 3) +
geom_smooth(method = "lm", formula = y ~ poly(x, 4), se = FALSE, linetype = 4)
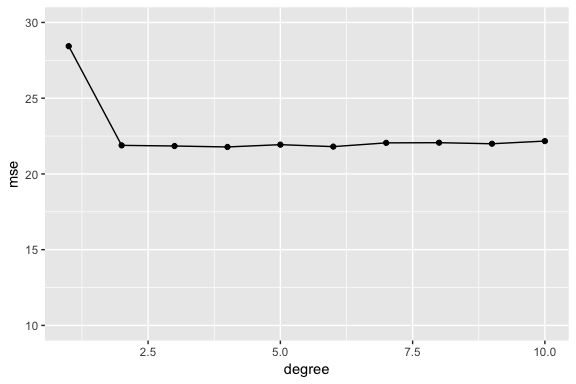
Let’s go ahead and do the traditional validation set approach to split our data into a training and testing set. Then we’ll fit 10 different models ranging from a linear model to a 10th degree polynomial model. The results show us there is a steep decline in our test error (MSE) rate when we go from a linear model to a quadratic model; however, the MSE flatlines beyond that point suggesting that adding more polynomial degrees likely does not improve the model performance.
set.seed(1)
sample <- sample(c(TRUE, FALSE), nrow(auto), replace = T, prob = c(0.6,0.4))
train <- auto[sample, ]
test <- auto[!sample, ]
# loop for first ten polynomial
mse.df <- tibble(degree = 1:10, mse = NA)
for(i in 1:10) {
lm.fit <- lm(mpg ~ poly(horsepower, i), data = train)
mse.df[i, 2] <- mean((test$mpg - predict(lm.fit, test))^2)
}
ggplot(mse.df, aes(degree, mse)) +
geom_line() +
geom_point() +
ylim(c(10, 30))
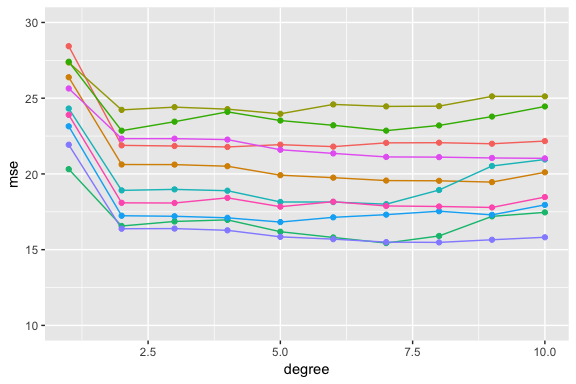
However, our MSE is dependent on our training and test samples. If we repeat the process of randomly splitting the sample set into two parts, we will get a somewhat different estimate for the test MSE each time. I illustrate below, which displays ten different validation set MSE curves from the auto data set, produced using ten different random splits of the observations into training and validation sets. All ten curves indicate that the model with a quadratic term has a dramatically smaller validation set MSE than the model with only a linear term. Furthermore, all ten curves indicate that there is not much benefit in including cubic or higher-order polynomial terms in the model. But it is worth noting that each of the ten curves results in a different test MSE estimate for each of the ten regression models considered. And there is no consensus among the curves as to which model results in the smallest validation set MSE.
mse.df.2 <- tibble(sample = vector("integer", 100),
degree = vector("integer", 100),
mse = vector("double", 100))
counter <- 1
for(i in 1:10) {
# random sample
set.seed(i)
sample <- sample(c(TRUE, FALSE), nrow(auto), replace = T, prob = c(0.6,0.4))
train <- auto[sample, ]
test <- auto[!sample, ]
# modeling
for(j in 1:10) {
lm.fit <- lm(mpg ~ poly(horsepower, j), data = train)
# add degree & mse values
mse.df.2[counter, 2] <- j
mse.df.2[counter, 3] <- mean((test$mpg - predict(lm.fit, test))^2)
# add sample identifier
mse.df.2[counter, 1] <- i
counter <- counter + 1
}
next
}
ggplot(mse.df.2, aes(degree, mse, color = factor(sample))) +
geom_line(show.legend = FALSE) +
geom_point(show.legend = FALSE) +
ylim(c(10, 30))
A second concern with the validation approach, only a subset of the observations, those that are included in the training set rather than in the validation set, are used to fit the model. Since statistical methods tend to perform worse when trained on fewer observations, this suggests that the validation set error rate may tend to overestimate the test error rate for the model fit on the entire data set.
We can address these concerns using cross-validation methods.
Leave-one-out cross-validation (LOOCV) is closely related to the validation set approach as it involves splitting the set of observations into two parts. However, instead of creating two subsets of comparable size (i.e. 60% training, 40% validation), a single observation () is used for the validation set, and the remaining observations {} make up the training set. The statistical learning method is fit on the training observations, and a prediction is made for the excluded observation. Since the validation observation () was not used in the fitting process, the estimate error provides an approximately unbiased estimate for the test error. But even though is unbiased for the test error, it is a poor estimate because it is highly variable, since it is based upon a single observation ().
However, we can repeat the procedure by selecting a different row () for the validation data, training the statistical learning procedure on the other observations and computing . We can repeate this approach n times, where each time we holdout a different, single observation to validate on. This produces a total of n squared errors, . The LOOCV estimate for the test MSE is the average of these n test error estimates:
To perform this procedure in R we first need to understand an important nuance. In the logistic regression tutorial, we used the glm function to perform logistic regression by passing in the family = "binomial" argument. But if we use glm to fit a model without passing in the family argument, then it performs linear regression, just like the lm function. So, for instance:
glm.fit <- glm(mpg ~ horsepower, data = auto)
coef(glm.fit)
## (Intercept) horsepower
## 39.9358610 -0.1578447
is the same as
lm.fit <- lm(mpg ~ horsepower, data = auto)
coef(lm.fit)
## (Intercept) horsepower
## 39.9358610 -0.1578447
Why is this important? Because we can perform LOOCV for any generalized linear model using glm and the cv.glm function from the boot package. boot provides extensive facilities for bootstrapping and related resampling methods. You can bootstrap a single statistic (e.g. a median), a vector (e.g., regression weights), or as you’ll see in this tutorial perform cross-validation. To perform LOOCV for a given generalized linear model we simply:
glmcv.glm# step 1: fit model
glm.fit <- glm(mpg ~ horsepower, data = auto)
# setp 2: perform LOOCV across entire data set
loocv.err <- cv.glm(auto, glm.fit)
str(loocv.err)
## List of 4
## $ call : language cv.glm(data = auto, glmfit = glm.fit)
## $ K : num 392
## $ delta: num [1:2] 24.2 24.2
## $ seed : int [1:626] 403 392 -1703707781 1994959178 434562476 -1277611857 -1105401243 1020654108 526650482 -1538305299 ...
cv.glm provides a list with 4 outputs:
The result we primarily care about is the cross-validation estimate of test error (Eq. 1). Our cross-validation estimate for the test error is approximately 24.23. This estimate is a far less biased estimate of the test error compared to our single test MSE produced by a training - testing validation approach.
loocv.err$delta[1]
## [1] 24.23151
We can repeat this procedure to estimate an ubiased MSE across multiple model fits. For example, to assess multiple polynomial fits (as we did above) to identify the one that represents the best fit we can integrate this procedure into a function. Here we develop a function that computes the LOOCV MSE based on specified polynomial degree. We then feed this function (via map_dbl) values 1-5 to compute the first through fifth polynomials.
# create function that computes LOOCV MSE based on specified polynomial degree
loocv_error <- function(x) {
glm.fit <- glm(mpg ~ poly(horsepower, x), data = auto)
cv.glm(auto, glm.fit)$delta[1]
}
# compute LOOCV MSE for polynomial degrees 1-5
library(purrr)
1:5 %>% map_dbl(loocv_error)
## [1] 24.23151 19.24821 19.33498 19.42443 19.03321
Our results illustrate a sharp drop in the estimated test MSE between the linear and quadratic fits, but then no clear improvement from using higher-order polynomials. Thus, our unbiased MSEs suggest that using a 2nd polynomial (quadratic fit) is likely the optimal model balancing interpretation and low test errors.
This LOOCV approach can be used with any kind of predictive modeling. For example we could use it with logistic regression or linear discriminant analysis. Unfortunately, this can be very time consuming approach if n is large, you’re trying to loop through many models (i.e. 1-10 polynomials), and if each individual model is slow to fit. For example, if we wanted to perform this approach on the ggplot2::diamonds data set for a linear regression model, which contains 53,940 observations, the computation time is nearly 30 minutes!
# DO NOT RUN THIS CODE - YOU WILL BE WAITING A LONG TIME!!
system.time({
diamonds.fit <- glm(price ~ carat + cut + color + clarity, data = diamonds)
cv.glm(diamonds, diamonds.fit)
})
# user system elapsed
# 1739.041 285.496 2035.062
An alternative to LOOCV is the k-fold cross validation approach. This resampling method involves randomly dividing the data into k groups (aka folds) of approximately equal size. The first fold is treated as a validation set, and the statistical method is fit on the remaining data. The mean squared error, , is then computed on the observations in the held-out fold. This procedure is repeated k times; each time, a different group of observations is treated as the validation set. This process results in k estimates of the test error, . Thus, the k-fold CV estimate is computed by averaging these values,
It is not hard to see that LOOCV is a special case of k-fold approach in which k is set to equal n. However, using the k-fold approach, one typically uses k = 5 or k = 10. This can substantially reduce the computational burden of LOOCV. Furthermore, there has been sufficient empirical evidence that demonstrates using 5-10 folds yield surprisingly accurate test error rate estimates (see chapter 5 of ISLR for more details1).
We can implement the k-fold approach just as we did with the LOOCV approach. The only difference is incorporating the K = 10 argument that we include in the cv.glm function. Below illustrates our k-fold MSE values for the different polynomial models on our auto data. When compared to the LOOCV outputs we see that the results are nearly identical.
# create function that computes k-fold MSE based on specified polynomial degree
kfcv_error <- function(x) {
glm.fit <- glm(mpg ~ poly(horsepower, x), data = auto)
cv.glm(auto, glm.fit, K = 10)$delta[1]
}
# compute k-fold MSE for polynomial degrees 1-5
1:5 %>% map_dbl(kfcv_error)
## [1] 24.56850 19.22648 19.29535 19.46601 19.24090
# compare to LOOCV MSE values
1:5 %>% map_dbl(loocv_error)
## [1] 24.23151 19.24821 19.33498 19.42443 19.03321
We can also illustrate the computational advantage of the k-fold approach. As we saw, using LOOCV on the diamonds data set took nearly 30 minutes whereas using the k-fold approach only takes about 4 seconds.
system.time({
diamonds.fit <- glm(price ~ carat + cut + color + clarity, data = diamonds)
cv.glm(diamonds, diamonds.fit, K = 10)
})
## user system elapsed
## 3.760 0.564 4.347
We can apply this same approach to classification problems as well. For example, in the previous tutorial we compared the performance of a logistic regression, linear discriminant analysis (LDA), and quadratic discriminant analysis (QDA) on some stock market data using the traditional training vs. testing (60%/40%) data splitting approach. We could’ve performed the same assessment using cross validation. In the classification setting, the LOOCV error rate takes the form
where . The k-fold CV error rate and validation set error rates are defined analogously.
Consequently, for the logistic regression we use cv.glm to perform a k-fold cross validation. The end result is an estimated CV error rate of .5. (Note: since the response variable is binary we incorporate a new cost function to compute the estimated error rate in Eq. 3)
stock <- ISLR::Smarket
# fit logistic regression model
glm.fit <- glm(Direction ~ Lag1 + Lag2, family = binomial, data = stock)
# The cost function here correlates to that in Eq. 3
cost <- function(r, pi = 0) mean(abs(r - pi) > 0.5)
# compute the k-fold estimated error with our cost function
cv.glm(stock, glm.fit, cost, K = 10)$delta[1]
## [1] 0.4984
To performm cross validation with our LDA and QDA models we use a slightly different approach. Both the lda and qda functions have built-in cross validation arguments. Thus, setting CV = TRUE within these functions will result in a LOOCV execution and the class and posterior probabilities are a product of this cross validation.
library(MASS)
# fit discriminant analysis models with CV = TRUE for LOOCV
lda.fit <- lda(Direction ~ Lag1 + Lag2, CV = TRUE, data = stock)
qda.fit <- qda(Direction ~ Lag1 + Lag2, CV = TRUE, data = stock)
# compute estimated test error based on cross validation
mean(lda.fit$class != stock$Direction)
## [1] 0.4816
mean(qda.fit$class != stock$Direction)
## [1] 0.4872
Thus, the results are similar to what we saw in the previous tutorial, none of these models do an exceptional (or even decent!) job. However, we see that the LOOCV estimated error for the QDA model (.487) is fairly higher than what we saw in the train-test validation approach (.40). This suggests that our previous QDA model with the train-test validation approach may have been a bit optimistically biased!
Bootstrapping is a widely applicable and extremely powerful statistical tool that can be used to quantify the uncertainty associated with a given estimator or statistical learning method. As a simple example, bootstraping can be used to estimate the standard errors of the coefficients from a linear regression fit. In the case of linear regression, this is not particularly useful, since we saw in the linear regression tutorial that R provides such standard errors automatically. However, the power of the bootstrap lies in the fact that it can be easily applied to a wide range of statistical learning methods, including some for which a measure of variability is otherwise difficult to obtain and is not automatically output by statistical software.
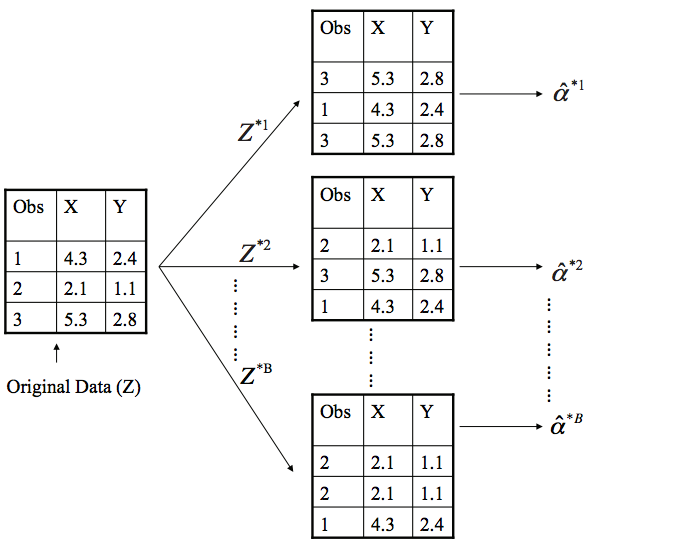
In essence bootstrapping repeatedly draws independent samples from our data set to create bootstrap data sets. This sample is performed with replacement, which means that the same observation can be sampled more than once. The figure below from the ISLR1 book depicts the bootsrap approach on a small data set (n = 3).
Each bootstrap data set () contains n observations, sampled with replacement from the original data set. Each bootstrap is used to compute the estimated statistic we are interested in (). We can then use all the bootstrapped data sets to compute the standard error of desired statistic as
Thus, serves as an estimate of the standard error of estimated from the original data set. Let’s look at how we can implement this in R on a couple of simple examples:
Performing a bootstrap analysis in R entails two steps:
boot function from the boot package to perform the boostrappingIn this example we’ll use the ISLR::Portfolio data set. This data set contains the returns for two investment assets (X and Y). Here, our goal is going to be minimizing the risk of investing a fixed sum of money in each asset. Mathematically, we can achieve this by minimizing the variance of our investment using the statistic
Thus, we need to create a function that will compute this test statistic:
statistic <- function(data, index) {
x <- data$X[index]
y <- data$Y[index]
(var(y) - cov(x, y)) / (var(x) + var(y) - 2* cov(x, y))
}
Now we can compute for a specified subset of our portfolio data:
portfolio <- ISLR::Portfolio
# compute our statistic for all 100 observations
statistic(portfolio, 1:100)
## [1] 0.5758321
Next, we can use sample to randomly select 100 observations from the range 1 to 100, with replacement. This is equivalent to constructing a new bootstrap data set and recomputing based on the new data set.
statistic(portfolio, sample(100, 100, replace = TRUE))
## [1] 0.7661566
If you re-ran this function several times you’ll see that you are getting a different output each time. What we want to do is run this many times, record our output each time, and then compute a valid standard error of all the outputs. To do this we can use boot and supply it our original data, the function that computes the test statistic, and the number of bootstrap replicates (R).
set.seed(123)
boot(portfolio, statistic, R = 1000)
##
## ORDINARY NONPARAMETRIC BOOTSTRAP
##
##
## Call:
## boot(data = portfolio, statistic = statistic, R = 1000)
##
##
## Bootstrap Statistics :
## original bias std. error
## t1* 0.5758321 0.002396754 0.08752118
The final output shows that using the original data, , and it also provides the bootstrap estimate of our standard error .
Once we generate the bootstrap estimates we can also view the confidence intervals with boot.ci and plot our results:
set.seed(123)
result <- boot(portfolio, statistic, R = 1000)
boot.ci(result, type = "basic")
## BOOTSTRAP CONFIDENCE INTERVAL CALCULATIONS
## Based on 1000 bootstrap replicates
##
## CALL :
## boot.ci(boot.out = result, type = "basic")
##
## Intervals :
## Level Basic
## 95% ( 0.3958, 0.7376 )
## Calculations and Intervals on Original Scale
plot(result)
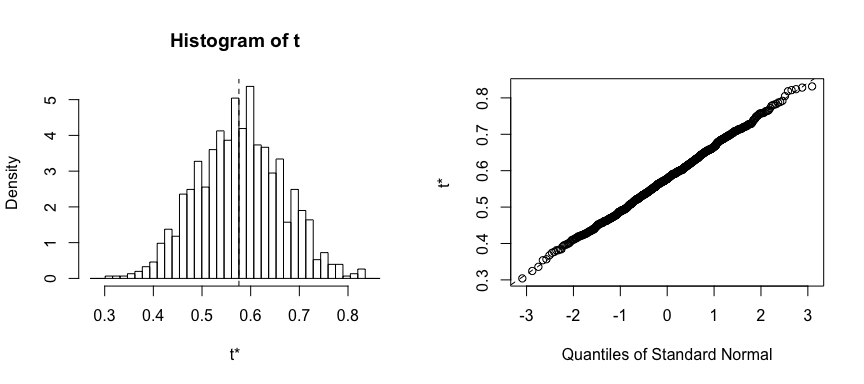
We can use this same concept to assess the variability of the coefficient estimates and predictions from a statistical learning method such as linear regression. For instance, here we’ll assess the variability of the estimates for and , the intercept and slope terms for the linear regression model that uses horsepower to predict mpg in our auto data set.
First, we create the function to compute the statistic of interest. We can apply this to our entire data set to get the baseline coefficients.
statistic <- function(data, index) {
lm.fit <- lm(mpg ~ horsepower, data = data, subset = index)
coef(lm.fit)
}
statistic(auto, 1:392)
## (Intercept) horsepower
## 39.9358610 -0.1578447
Now we can inject this into the boot function to compute the bootstrapped standard error estimate:
set.seed(123)
boot(auto, statistic, 1000)
##
## ORDINARY NONPARAMETRIC BOOTSTRAP
##
##
## Call:
## boot(data = auto, statistic = statistic, R = 1000)
##
##
## Bootstrap Statistics :
## original bias std. error
## t1* 39.9358610 0.0295956008 0.863541674
## t2* -0.1578447 -0.0002940364 0.007598619
This indicates that the bootstrap estimate for is 0.86, and that the bootstrap estimate for is 0.0076. If we compare these to the standard errors provided by the summary function we see a difference.
summary(lm(mpg ~ horsepower, data = auto))
##
## Call:
## lm(formula = mpg ~ horsepower, data = auto)
##
## Residuals:
## Min 1Q Median 3Q Max
## -13.5710 -3.2592 -0.3435 2.7630 16.9240
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 39.935861 0.717499 55.66 <2e-16 ***
## horsepower -0.157845 0.006446 -24.49 <2e-16 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 4.906 on 390 degrees of freedom
## Multiple R-squared: 0.6059, Adjusted R-squared: 0.6049
## F-statistic: 599.7 on 1 and 390 DF, p-value: < 2.2e-16
This difference suggests the standard errors provided by summary may be biased. That is, certain assumptions may be violated which is causing the standard errors in the non-bootstrap approach to be different than those in the bootstrap approach.
If you remember from earlier in the tutorial we found that a quadratic fit appeared to be the most approapriate for the relationship between mpg and horsepower. Lets adjust our code to capture this fit and see if we notice a difference with our outputs.
quad.statistic <- function(data, index) {
lm.fit <- lm(mpg ~ poly(horsepower, 2), data = data, subset = index)
coef(lm.fit)
}
set.seed(1)
boot(auto, quad.statistic, 1000)
##
## ORDINARY NONPARAMETRIC BOOTSTRAP
##
##
## Call:
## boot(data = auto, statistic = quad.statistic, R = 1000)
##
##
## Bootstrap Statistics :
## original bias std. error
## t1* 23.44592 0.003943212 0.2255528
## t2* -120.13774 0.117312678 3.7008952
## t3* 44.08953 0.047449584 4.3294215
Now if we compare the standard errors between the bootstrap approach and the non-bootstrap approach we see the standard errors align more closely. This better correspondence between the bootstrap estimates and the standard estimates suggest a better model fit. Thus, bootstrapping provides an additional method for assessing the adequacy of our model’s fit.
summary(lm(mpg ~ poly(horsepower, 2), data = auto))
##
## Call:
## lm(formula = mpg ~ poly(horsepower, 2), data = auto)
##
## Residuals:
## Min 1Q Median 3Q Max
## -14.7135 -2.5943 -0.0859 2.2868 15.8961
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 23.4459 0.2209 106.13 <2e-16 ***
## poly(horsepower, 2)1 -120.1377 4.3739 -27.47 <2e-16 ***
## poly(horsepower, 2)2 44.0895 4.3739 10.08 <2e-16 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 4.374 on 389 degrees of freedom
## Multiple R-squared: 0.6876, Adjusted R-squared: 0.686
## F-statistic: 428 on 2 and 389 DF, p-value: < 2.2e-16
This will get you started with resampling methods; however, understand that there are many approaches for resampling and even more options within R to implement these approaches. The following resources will help you learn more:
This tutorial was built as a supplement to chapter 5 of An Introduction to Statistical Learning ↩ ↩2 ↩3