02 Oct 2018
 Historically, data has been available to us in the form of numeric (i.e. customer age, income, household size) and categorical features (i.e. region, department, gender). However, as organizations look for ways to collect new forms of information such as unstructured text, images, social media posts, etcetera, we need to understand how to convert this information into structured features to use in data science tasks such as customer segmentation or prediction tasks. In this post, we explore a few fundamental feature engineering approaches that we can start using to convert unstructured text into structured features.
Historically, data has been available to us in the form of numeric (i.e. customer age, income, household size) and categorical features (i.e. region, department, gender). However, as organizations look for ways to collect new forms of information such as unstructured text, images, social media posts, etcetera, we need to understand how to convert this information into structured features to use in data science tasks such as customer segmentation or prediction tasks. In this post, we explore a few fundamental feature engineering approaches that we can start using to convert unstructured text into structured features.
08 Sep 2018
 Several previous tutorials (i.e. linear regression, logistic regression, regularized regression) discussed algorithms that are intrinsically linear. Many of these models can be adapted to nonlinear patterns in the data by manually adding model terms (i.e. squared terms, interaction effects); however, to do so you must know the specific nature of the nonlinearity a priori. Alternatively, there are numerous algorithms that are inherently nonlinear. When using these models, the exact form of the nonlinearity does not need to be known explicitly or specified prior to model training. Rather, these algorithms will search for, and discover, nonlinearities in the data that help maximize predictive accuracy. This latest tutorial discusses multivariate adaptive regression splines (MARS), an algorithm that essentially creates a piecewise linear model which provides an intuitive stepping block into nonlinearity after grasping the concept of linear regression and other intrinsically linear models.
Several previous tutorials (i.e. linear regression, logistic regression, regularized regression) discussed algorithms that are intrinsically linear. Many of these models can be adapted to nonlinear patterns in the data by manually adding model terms (i.e. squared terms, interaction effects); however, to do so you must know the specific nature of the nonlinearity a priori. Alternatively, there are numerous algorithms that are inherently nonlinear. When using these models, the exact form of the nonlinearity does not need to be known explicitly or specified prior to model training. Rather, these algorithms will search for, and discover, nonlinearities in the data that help maximize predictive accuracy. This latest tutorial discusses multivariate adaptive regression splines (MARS), an algorithm that essentially creates a piecewise linear model which provides an intuitive stepping block into nonlinearity after grasping the concept of linear regression and other intrinsically linear models.
01 Aug 2018

With machine learning interpretability growing in importance, several R packages designed to provide this capability are gaining in popularity. In recent blog posts I assessed lime for model agnostic local interpretability functionality and DALEX for both local and global machine learning explanation plots. This newest tutorial examines the iml package to assess its functionality in providing machine learning interpretability to help you determine if it should become part of your preferred machine learning toolbox.
11 Jul 2018

As advanced machine learning algorithms are gaining acceptance across many organizations and domains, machine learning interpretability is growing in importance to help extract insight and clarity regarding how these algorithms are performing and why one prediction is made over another. There are many methodologies to interpret machine learning results (i.e. variable importance via permutation, partial dependence plots, local interpretable model-agnostic explanations), and many machine learning R packages implement their own versions of one or more methodologies. However, some recent R packages that focus purely on ML interpretability agnostic to any specific ML algorithm are gaining popularity. One such package is DALEX and this latest tutorial covers what this package does (and does not do) so that you can determine if it should become part of your preferred machine learning toolbox.
14 Jun 2018
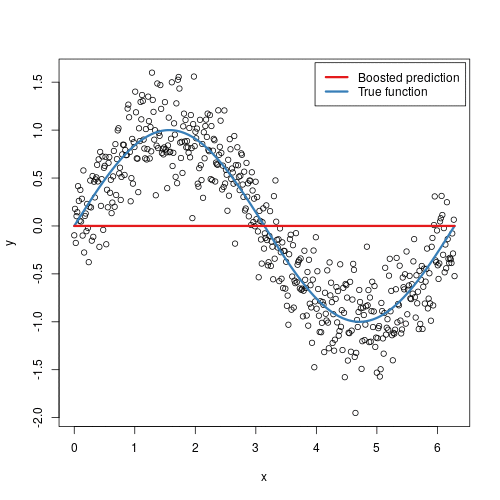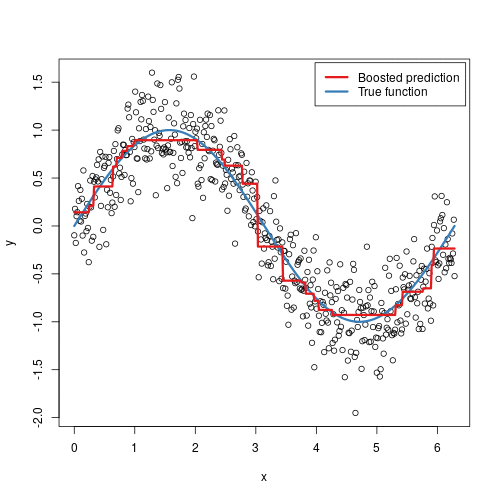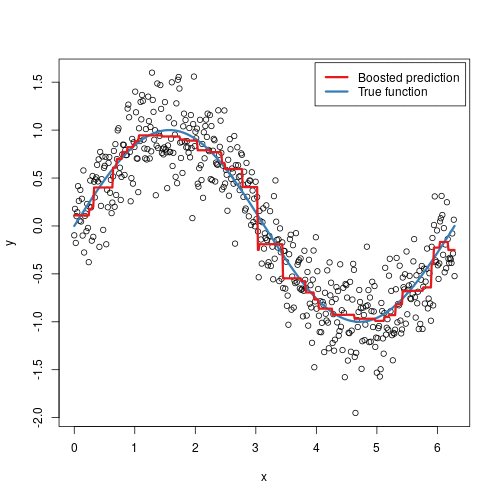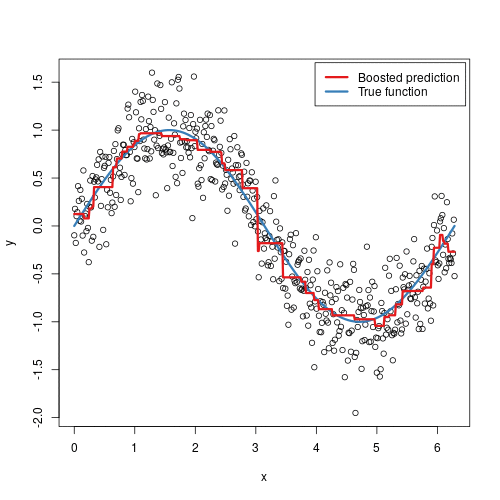 Gradient boosting machines (GBMs) are an extremely popular machine learning algorithm that have proven successful across many domains and is one of the leading methods for winning Kaggle competitions. Whereas random forests build an ensemble of deep independent trees, GBMs build an ensemble of shallow and weak successive trees with each tree learning and improving on the previous. When combined, these many weak successive trees produce a powerful “committee” that are often hard to beat with other algorithms. This latest tutorial covers the fundamentals of GBMs for regression problems.
Gradient boosting machines (GBMs) are an extremely popular machine learning algorithm that have proven successful across many domains and is one of the leading methods for winning Kaggle competitions. Whereas random forests build an ensemble of deep independent trees, GBMs build an ensemble of shallow and weak successive trees with each tree learning and improving on the previous. When combined, these many weak successive trees produce a powerful “committee” that are often hard to beat with other algorithms. This latest tutorial covers the fundamentals of GBMs for regression problems.