![]() Follow me on twitter @bradleyboehmke
Follow me on twitter @bradleyboehmke
![]() Follow me on twitter @bradleyboehmke
Follow me on twitter @bradleyboehmke
![]()
With machine learning interpretability growing in importance, several R packages designed to provide this capability are gaining in popularity. In recent blog posts I assessed lime for model agnostic local interpretability functionality and DALEX for both local and global machine learning explanation plots. This post examines the iml package to assess its functionality in providing machine learning interpretability to help you determine if it should become part of your preferred machine learning toolbox.
iml does and does not do.iml procedures: necessary functions for downstream explainers.The iml package is probably the most robust ML interpretability package available. It provides both global and local model-agnostic interpretation methods. Although the interaction functions are notably slow, the other functions are faster or comparable to existing packages we use or have tested. I definitely recommend adding iml to your preferred ML toolkit. The following provides a quick list of some of its pros and cons:
Advantages
ggplot2 which allows for easy customizationDisadvantages
DALEX.lime.I leverage the following packages:
# load required packages
library(rsample) # data splitting
library(ggplot2) # allows extension of visualizations
library(dplyr) # basic data transformation
library(h2o) # machine learning modeling
library(iml) # ML interprtation
# initialize h2o session
h2o.no_progress()
h2o.init()
## Connection successful!
##
## R is connected to the H2O cluster:
## H2O cluster uptime: 4 hours 28 minutes
## H2O cluster timezone: America/New_York
## H2O data parsing timezone: UTC
## H2O cluster version: 3.18.0.11
## H2O cluster version age: 2 months and 8 days
## H2O cluster name: H2O_started_from_R_bradboehmke_gbc793
## H2O cluster total nodes: 1
## H2O cluster total memory: 1.01 GB
## H2O cluster total cores: 4
## H2O cluster allowed cores: 4
## H2O cluster healthy: TRUE
## H2O Connection ip: localhost
## H2O Connection port: 54321
## H2O Connection proxy: NA
## H2O Internal Security: FALSE
## H2O API Extensions: XGBoost, Algos, AutoML, Core V3, Core V4
## R Version: R version 3.5.1 (2018-07-02)
To demonstrate DALEX’s capabilities we’ll use the employee attrition data that has been included in the rsample package. This demonstrates a binary classification problem (“Yes” vs. “No”) but the same process that you’ll observe can be used for a regression problem.
I perform a few house cleaning tasks on the data prior to converting to an h2o object and splitting.
NOTE: The surrogate tree function uses partykit::cpart, which requires all predictors to be numeric or factors. Consequently, we need to coerce any character predictors to factors (or ordinal encode).
# classification data
df <- rsample::attrition %>%
mutate_if(is.ordered, factor, ordered = FALSE) %>%
mutate(Attrition = recode(Attrition, "Yes" = "1", "No" = "0") %>% factor(levels = c("1", "0")))
# convert to h2o object
df.h2o <- as.h2o(df)
# create train, validation, and test splits
set.seed(123)
splits <- h2o.splitFrame(df.h2o, ratios = c(.7, .15), destination_frames = c("train","valid","test"))
names(splits) <- c("train","valid","test")
# variable names for resonse & features
y <- "Attrition"
x <- setdiff(names(df), y)
We will explore how to visualize a few of the more common machine learning algorithms implemented with h2o. For brevity I train default models and do not emphasize hyperparameter tuning. The following produces a regularized logistic regression, random forest, and gradient boosting machine models; all of which provide AUCs ranging between .75-.79. Although these models have distinct AUC scores, our objective is to understand how these models come to this conclusion in similar or different ways based on underlying logic and data structure.
# elastic net model
glm <- h2o.glm(
x = x,
y = y,
training_frame = splits$train,
validation_frame = splits$valid,
family = "binomial",
seed = 123
)
# random forest model
rf <- h2o.randomForest(
x = x,
y = y,
training_frame = splits$train,
validation_frame = splits$valid,
ntrees = 1000,
stopping_metric = "AUC",
stopping_rounds = 10,
stopping_tolerance = 0.005,
seed = 123
)
# gradient boosting machine model
gbm <- h2o.gbm(
x = x,
y = y,
training_frame = splits$train,
validation_frame = splits$valid,
ntrees = 1000,
stopping_metric = "AUC",
stopping_rounds = 10,
stopping_tolerance = 0.005,
seed = 123
)
# model performance
h2o.auc(glm, valid = TRUE)
## [1] 0.7870935
h2o.auc(rf, valid = TRUE)
## [1] 0.7681021
h2o.auc(gbm, valid = TRUE)
## [1] 0.7468242
iml proceduresIn order to work with iml, we need to adapt our data a bit so that we have the following three components:
data.frame, cannot be an H2OFrame or other class).iml has internal support for some machine learning packages (i.e. mlr, caret, randomForest). However, to use iml with several of the more popular packages being used today (i.e. h2o, ranger, xgboost) we need to create a custom function that will take a data set (again must be of class data.frame) and provide the predicted values as a vector.# 1. create a data frame with just the features
features <- as.data.frame(splits$valid) %>% select(-Attrition)
# 2. Create a vector with the actual responses
response <- as.numeric(as.vector(splits$valid$Attrition))
# 3. Create custom predict function that returns the predicted values as a
# vector (probability of purchasing in our example)
pred <- function(model, newdata) {
results <- as.data.frame(h2o.predict(model, as.h2o(newdata)))
return(results[[3L]])
}
# example of prediction output
pred(rf, features) %>% head()
## [1] 0.18181818 0.27272727 0.06060606 0.54545455 0.03030303 0.42424242
Once we have these three components we can create a predictor object. Similar to DALEX and lime, the predictor object holds the model, the data, and the class labels to be applied to downstream functions. A unique characteristic of the iml package is that it uses R6 classes, which is rather rare. To main differences between R6 classes and the normal S3 and S4 classes we typically work with are:
These properties make R6 objects behave more like objects in programming languages such as Python. So to construct a new Predictor object, you call the new() method which belongs to the R6 Predictor object and you use $ to access new():
# create predictor object to pass to explainer functions
predictor.glm <- Predictor$new(
model = glm,
data = features,
y = response,
predict.fun = pred,
class = "classification"
)
predictor.rf <- Predictor$new(
model = rf,
data = features,
y = response,
predict.fun = pred,
class = "classification"
)
predictor.gbm <- Predictor$new(
model = gbm,
data = features,
y = response,
predict.fun = pred,
class = "classification"
)
# structure of predictor object
str(predictor.gbm)
## Classes 'Predictor', 'R6' <Predictor>
## Public:
## class: classification
## clone: function (deep = FALSE)
## data: Data, R6
## initialize: function (model = NULL, data, predict.fun = NULL, y = NULL, class = NULL)
## model: H2OBinomialModel
## predict: function (newdata)
## prediction.colnames: NULL
## prediction.function: function (newdata)
## print: function ()
## task: unknown
## Private:
## predictionChecked: FALSE
iml provides a variety of ways to understand our models from a global perspective.
We can measure how important each feature is for the predictions with FeatureImp. The feature importance measure works by calculating the increase of the model’s prediction error after permuting the feature. A feature is “important” if permuting its values increases the model error, because the model relied on the feature for the prediction. A feature is “unimportant” if permuting its values keeps the model error unchanged, because the model ignored the feature for the prediction. This model agnostic approach is based on (Breiman, 2001; Fisher et al, 2018) and follows the given steps:
For any given loss function do
1: compute loss function for original model
2: for variable i in {1,...,p} do
| randomize values
| apply given ML model
| estimate loss function
| compute feature importance (permuted loss / original loss)
end
3. Sort variables by descending feature importance
We see that all three models find OverTime as the most influential variable; however, after that each model finds unique structure and signals within the data. Note: you can extract the results with imp.rf$results.
# compute feature importance with specified loss metric
imp.glm <- FeatureImp$new(predictor.glm, loss = "mse")
imp.rf <- FeatureImp$new(predictor.rf, loss = "mse")
imp.gbm <- FeatureImp$new(predictor.gbm, loss = "mse")
# plot output
p1 <- plot(imp.glm) + ggtitle("GLM")
p2 <- plot(imp.rf) + ggtitle("RF")
p3 <- plot(imp.gbm) + ggtitle("GBM")
gridExtra::grid.arrange(p1, p2, p3, nrow = 1)

Permutation-based approaches can become slow as your number of predictors grows. To assess variable importance for all 3 models in this example takes only 8 seconds. However, performing the same procedure on a data set with 80 predictors (AmesHousing::make_ames()) takes roughly 3 minutes. Although this is slower, it is comparable to other permutation-based implementations (i.e. DALEX, ranger).
system.time({
imp.glm <- FeatureImp$new(predictor.glm, loss = "mse")
imp.rf <- FeatureImp$new(predictor.rf, loss = "mse")
imp.gbm <- FeatureImp$new(predictor.gbm, loss = "mse")
})
## user system elapsed
## 2.982 0.112 8.164
The following lists some advantages and disadvantages to iml’s feature importance procedure.
Advantages:
ggplot2; we can add to or use our internal branding packages with itDisadvantages:
$results data frame if desiredThe Partial class implements partial dependence plots (PDPs) and individual conditional expectation (ICE) curves. The procedure follows the traditional methodology documented in Friedman (2001) and Goldstein et al. (2014) where the ICE curve for a certain feature illustrates the predicted value for each observation when we force each observation to take on the unique values of that feature. The PDP curve represents the average prediction across all observations.
For a selected predictor (x)
1. Determine grid space of j evenly spaced values across distribution of x
2: for value i in {1,...,j} of grid space do
| set x to i for all observations
| apply given ML model
| estimate predicted value
| if PDP: average predicted values across all observations
end
The following produces “ICE boxplots” and a PDP line (connects the averages of all observations for each response class) for the most important variable in all three models (OverTime). All three model show a sizable increase in the probability of employees attriting when working overtime. However, you will notice the random forest model experiences less of an increase in probability compared to the other two models.
glm.ot <- Partial$new(predictor.glm, "OverTime") %>% plot() + ggtitle("GLM")
rf.ot <- Partial$new(predictor.rf, "OverTime") %>% plot() + ggtitle("RF")
gbm.ot <- Partial$new(predictor.gbm, "OverTime") %>% plot() + ggtitle("GBM")
gridExtra::grid.arrange(glm.ot, rf.ot, gbm.ot, nrow = 1)

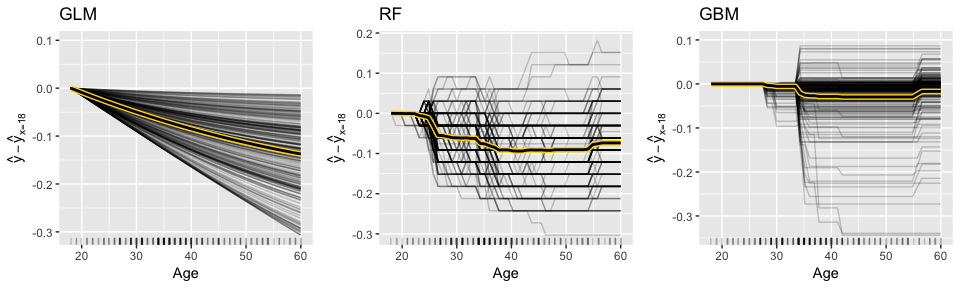
For continuous predictors you can reduce the grid space to make computation time more efficient and center the ICE curves. Note: to produce the centered ICE curves (right plot) you use ice$center and provide it the value to center on. This will modify the existing object in place (recall this is a unique characteristic of R6 objects are mutable). The following compares the marginal impact of age on the probability of attriting. The regularized regression model shows a monotonic decrease in the probability (the log-odds probability is linear) while the two tree-based approaches capture the non-linear, non-monotonic relationship.
# GLM model
glm.age <- Partial$new(predictor.glm, "Age", ice = TRUE, grid.size = 50)
glm.age$center(min(features$Age))
p1 <- plot(glm.age) + ggtitle("GLM")
# RF model
rf.age <- Partial$new(predictor.rf, "Age", ice = TRUE, grid.size = 50)
rf.age$center(min(features$Age))
p2 <- plot(rf.age) + ggtitle("RF")
# GBM model
gbm.age <- Partial$new(predictor.gbm, "Age", ice = TRUE, grid.size = 50)
gbm.age$center(min(features$Age))
p3 <- plot(gbm.age) + ggtitle("GBM")
gridExtra::grid.arrange(p1, p2, p3, nrow = 1)
Similar to pdp you can also compute and plot 2-way interactions. Here we assess how the interaction of MonthlyIncome and OverTime influences the predicted probability of attrition for all three models.
p1 <- Partial$new(predictor.glm, c("MonthlyIncome", "OverTime")) %>% plot() + ggtitle("GLM") + ylim(c(0, .4))
p2 <- Partial$new(predictor.rf, c("MonthlyIncome", "OverTime")) %>% plot() + ggtitle("RF") + ylim(c(0, .4))
p3 <- Partial$new(predictor.gbm, c("MonthlyIncome", "OverTime")) %>% plot() + ggtitle("GBM") + ylim(c(0, .4))
gridExtra::grid.arrange(p1, p2, p3, nrow = 1)

The following lists some advantages and disadvantages to iml’s PDP and ICE procedures.
Advantages:
DALEX)grid.size allows you to increase/reduce grid space of valuesDisadvantages:
DALEXA wonderful feature provided by iml is to measure how strongly features interact with each other. To measure interaction, iml uses the H-statistic proposed by Friedman and Popescu (2008). The H-statistic measures how much of the variation of the predicted outcome depends on the interaction of the features. There are two approaches to measure this. The first measures if a feature () interacts with any other feature. The algorithm performs the following steps:
1: for variable i in {1,...,p} do
| f(x) = estimate predicted values with original model
| pd(x) = partial dependence of variable i
| pd(!x) = partial dependence of all features excluding i
| upper = sum(f(x) - pd(x) - pd(!x))
| lower = variance(f(x))
| rho = upper / lower
end
2. Sort variables by descending rho (interaction strength)
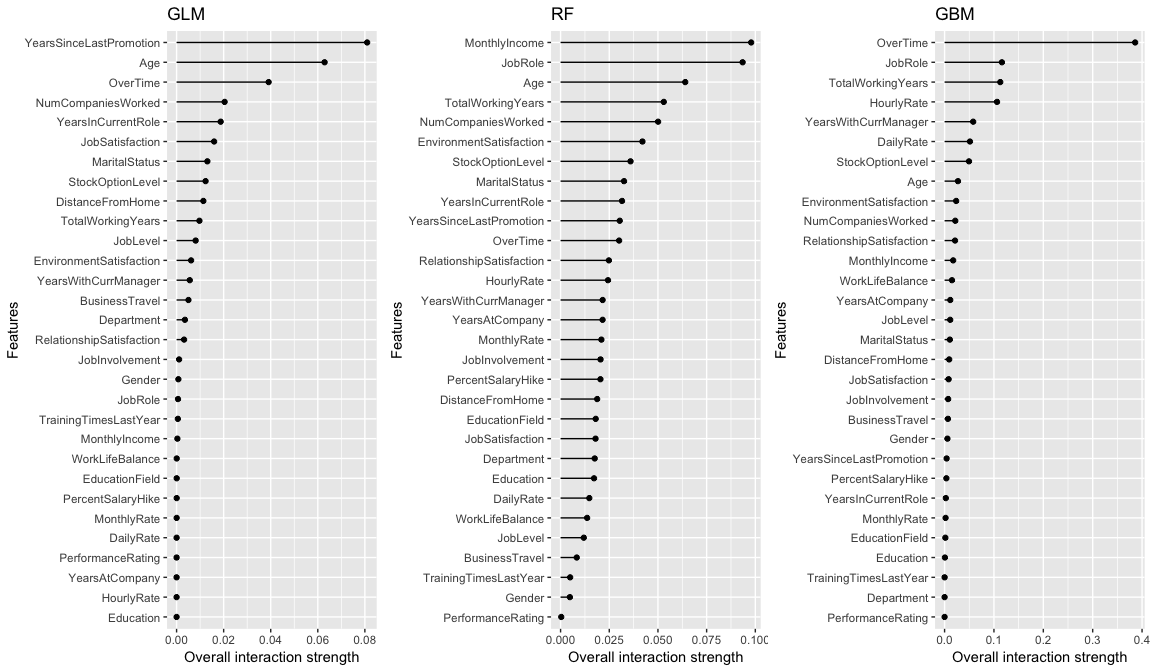
The intereaction strength () will be between 0 when there is no interaction at all and 1 if all of variation of the predicted outcome depends on a given interaction. All three models capture different interaction structures although some commonalities exist for different models (i.e. OverTime, Age, JobRole). The interaction effects are stronger in the tree based models versus the GLM model, with the GBM model having the strongest interaction effect of 0.4.
# identify variables with largest interactions in each model
interact.glm <- Interaction$new(predictor.glm) %>% plot() + ggtitle("GLM")
interact.rf <- Interaction$new(predictor.rf) %>% plot() + ggtitle("RF")
interact.gbm <- Interaction$new(predictor.gbm) %>% plot() + ggtitle("GBM")
# plot
gridExtra::grid.arrange(interact.glm, interact.rf, interact.gbm, nrow = 1)
Considering OverTime exhibits the strongest interaction signal, the next question is which other variable is this interaction the strongest. The second interaction approach measures the 2-way interaction strength of feature and and performs the following steps:
1: i = a selected variable of interest
2: for remaining variables j in {1,...,p} do
| pd(ij) = interaction partial dependence of variables i and j
| pd(i) = partial dependence of variable i
| pd(j) = partial dependence of variable j
| upper = sum(pd(ij) - pd(i) - pd(j))
| lower = variance(pd(ij))
| rho = upper / lower
end
3. Sort interaction relationship by descending rho (interaction strength)
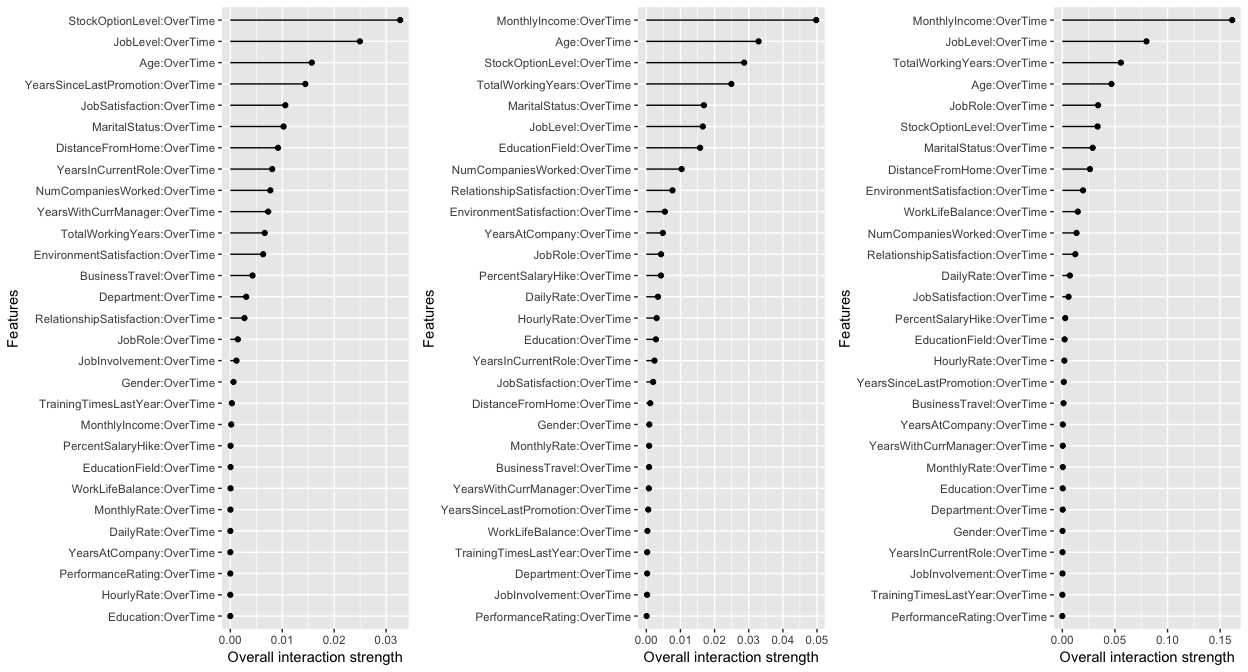
The following measures the two-way interactions of all variables with the OverTime variable. The two tree-based models show MonthlyIncome having the strongest interaction (although it is a week interaction since ). Identifying these interactions can be useful to understand which variables create co-denpendencies in our models behavior. It also helps us identify interactions to visualize with PDPs (which is why I showed the example of the OverTime and MonthlyIncome interaction PDP earlier).
# identify variables with largest interactions w/OverTime
interact.glm <- Interaction$new(predictor.glm, feature = "OverTime") %>% plot()
interact.rf <- Interaction$new(predictor.rf, feature = "OverTime") %>% plot()
interact.gbm <- Interaction$new(predictor.gbm, feature = "OverTime") %>% plot()
# plot
gridExtra::grid.arrange(interact.glm, interact.rf, interact.gbm, nrow = 1)
The H-statistic is not widely implemented so having this feature in iml is beneficial. However, its important to note that as your feature set grows, the H-statistic becomes computationally slow. For this data set, measuring the interactions across all three models only took 45 seconds and 68 seconds for the two-way interactions. However, for a wider data set such as AmesHousing::make_ames() where there are 80 predictors, this will up towards an hour to compute.
Another way to make the models more interpretable is to replace the “black box” model with a simpler model (aka “white box” model) such as a decision tree. This is known as a surrogate model in which we
1. apply original model and get predictions
2. choose an interpretable "white box" model (linear model, decision tree)
3. Train the interpretable model on the original dataset and its predictions
4. Measure how well the surrogate model replicates the prediction of the black box model
5. Interpret / visualize the surrogate model
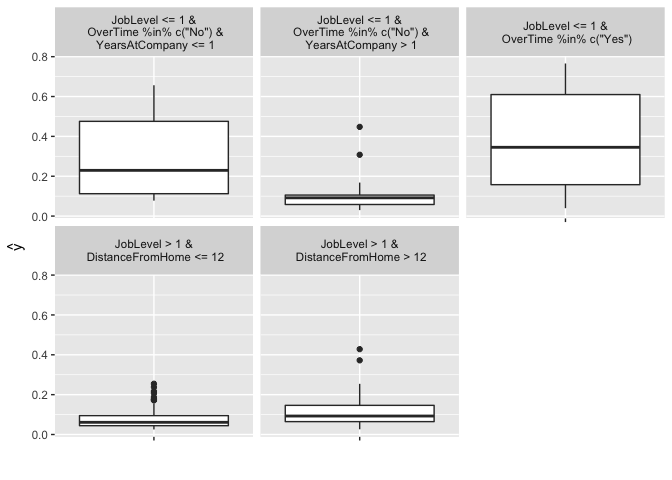
iml provides a simple decision tree surrogate approach, which leverages partykit::cpart. In this example we train a CART decision tree with max depth of 3 on our GBM model. You can see that the white box model does not do a good job of explaining the black box predictions (). The plot illustrates the distribution of the probability of attrition for each terminal node. We see an employee with JobLevel and DistanceFromHome has a very low probability of attriting.
# fit surrogate decision tree model
tree <- TreeSurrogate$new(predictor.gbm, maxdepth = 3)
# how well does this model fit the original results
tree$r.squared
## [1] 0.4384319
#
plot(tree)
When trying to explain a complicated machine learning model to decision makers, surrogate models can help simplify the process. However, its important to only use surrogate models for simplified explanations when they are actually good representatives of the black box model (in this example it is not).
In addition to providing global explanations of ML models, iml also provides two newer, but well accepted methods for local interpretation.
Local interpretation techniques provide methods to explain why an individual prediction was made for a given observation.
To illustrate, lets get two observations. The first represents the observation that our random forest model produces the highest probability of a attrition (observation 154 has a 0.666 probability of attrition) and the second represents the observation with the lowest probability (observation 28 has a 0 probability of attrition).
# identify obs with highest and lowest probabilities
(high <- predict(rf, splits$valid) %>% .[, 3] %>% as.vector() %>% which.max())
## [1] 154
(low <- predict(rf, splits$valid) %>% .[, 3] %>% as.vector() %>% which.min())
## [1] 28
# get these observations
high_prob_ob <- features[high, ]
low_prob_ob <- features[low, ]
iml implements its own version of local interpretable model-agnostic explanations (Ribeiro et al., 2016). Although it does not use the lime package directly, it does implement the same procedures (see lime tutorial).
A few notable items about iml implementation (see referenced tutorial above for these details within lime):
lime, can change distance metric (default is gower but accepts all distance functions provided by ?dist),lime, can change kernel (neighborhood size),lime, computationally efficient takes about 5 seconds to compute,lime, can be applied to multinomial responses,lime, uses the glmnet package to fit the local model; however…lime, only implements a ridge model (lime allows ridge, lasso, and more),lime, can only do one observation at a time (lime can do multiple),lime, does not provide fit metric such as () for the local model.The following fits a local model for the observation with the highest probability of attrition. In this example I look for the 10 variables in each model that are most influential in this observations predicted value (k = 10). The results show that the Age of the employee reduces the probability of attrition within all three models. Morever, all three models show that since this employee works OverTime, this is having a sizable increase in the probability of attrition. However, the tree-based models also identify the MaritalStatus and JobRole of this employee contributing to his/her increased probability of attrition.
# fit local model
lime.glm <- LocalModel$new(predictor.glm, k = 10, x.interest = high_prob_ob) %>% plot() + ggtitle("GLM")
lime.rf <- LocalModel$new(predictor.rf, k = 10, x.interest = high_prob_ob) %>% plot() + ggtitle("RF")
lime.gbm <- LocalModel$new(predictor.gbm, k = 10, x.interest = high_prob_ob) %>% plot() + ggtitle("GBM")
gridExtra::grid.arrange(lime.glm, lime.rf, lime.gbm, nrow = 1)

Here, I reapply the same model to low_prob_ob. Here, we see Age, JobLevel, and OverTime all having sizable influence on this employees very low predicted probability of attrition (zero).
# fit local model
lime.glm <- LocalModel$new(predictor.glm, k = 10, x.interest = low_prob_ob) %>% plot() + ggtitle("GLM")
lime.rf <- LocalModel$new(predictor.rf, k = 10, x.interest = low_prob_ob) %>% plot() + ggtitle("RF")
lime.gbm <- LocalModel$new(predictor.gbm, k = 10, x.interest = low_prob_ob) %>% plot() + ggtitle("GBM")
gridExtra::grid.arrange(lime.glm, lime.rf, lime.gbm, nrow = 1)

Although, LocalModel does not provide the fit metrics (i.e. ) for our local model, we can compare the local models predicted probability to the global (full) model’s predicted probability. For the high probability employee, the local model only predicts a 0.34 probability of attrition whereas the local model predicts a more accurate 0.12 probability of attrition for the low probability employee. This can help you guage the trustworthiness of the local model.
# high probability observation
predict(rf, splits$valid) %>% .[high, 3] # actual probability
## [1] 0.6666667
lime_high <- LocalModel$new(predictor.rf, k = 10, x.interest = high_prob_ob)
lime_high$predict(high_prob_ob) # predicted probability
## prediction
## 1 0.3371567
# low probability observation
predict(rf, splits$valid) %>% .[low, 3] # actual probability
## [1] 0
lime_low <- LocalModel$new(predictor.rf, k = 10, x.interest = low_prob_ob)
lime_low$predict(low_prob_ob) # predicted probability
## prediction
## 1 0.1224224
An alternative for explaining individual predictions is a method from coalitional game theory that produces whats called Shapley values (Lundberg & Lee, 2016). The idea behind Shapley values is to assess every combination of predictors to determine each predictors impact. Focusing on feature , the approach will test the accuracy of every combination of features not including and then test how adding to each combination improves the accuracy. Unfortunately, computing Shapley values is very computationally expensive. Consequently, iml implements an approximate Shapley estimation algorithm that follows the following steps:
ob = single observation of interest
1: for variables j in {1,...,p} do
| m = random sample from data set
| t = rbind(m, ob)
| f(all) = compute predictions for t
| f(!j) = compute predictions for t with feature j values randomized
| diff = sum(f(all) - f(!j))
| phi = mean(diff)
end
2. sort phi in decreasing order
The Shapley value () represents the contribution of each respective variable towards the predicted valued compared to the average prediction for the data set.
We use Shapley$new to create a new Shapley object. For this data set it takes about 9 seconds to compute. The time to compute is largely driven by the number of predictors but you can also control the sample size drawn (see sample.size argument) to help reduce compute time. If you look at the results, you will see that the predicted value of 0.667 is 0.496 larger than the average prediction of 0.17. The plot displays the contribution each predictor played in this difference of 0.496.
# compute Shapley values
shapley.rf <- Shapley$new(predictor.rf, x.interest = high_prob_ob)
# look at summary of results
shapley.rf
## Interpretation method: Shapley
## Predicted value: 0.666667, Average prediction: 0.170373 (diff = 0.496293)
##
## Analysed predictor:
## Prediction task: unknown
##
##
## Analysed data:
## Sampling from data.frame with 233 rows and 30 columns.
##
## Head of results:
## feature phi phi.var
## 1 Age 0.033030303 0.0033594902
## 2 BusinessTravel 0.039090909 0.0028808749
## 3 DailyRate 0.023030303 0.0017274675
## 4 Department -0.011515152 0.0008307130
## 5 DistanceFromHome -0.014545455 0.0006952908
## 6 Education -0.002424242 0.0005134912
## feature.value
## 1 Age=28
## 2 BusinessTravel=Travel_Frequently
## 3 DailyRate=791
## 4 Department=Research_Development
## 5 DistanceFromHome=1
## 6 Education=Master
#plot results
plot(shapley.rf)
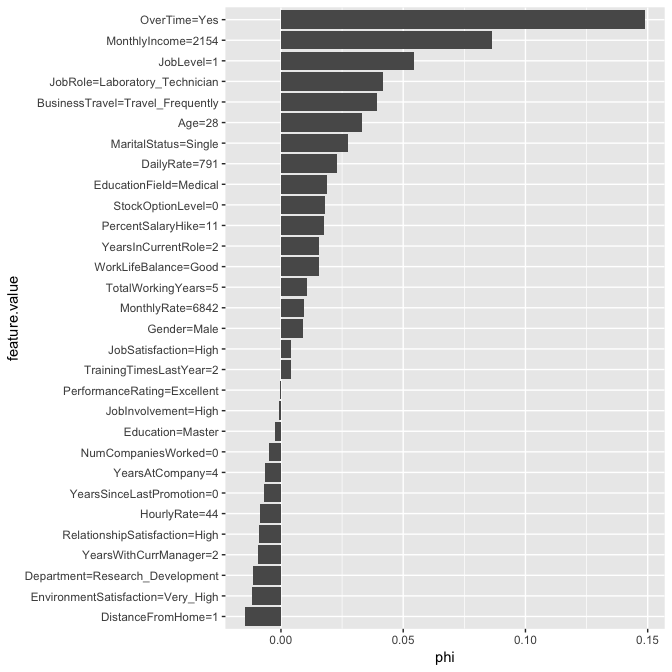
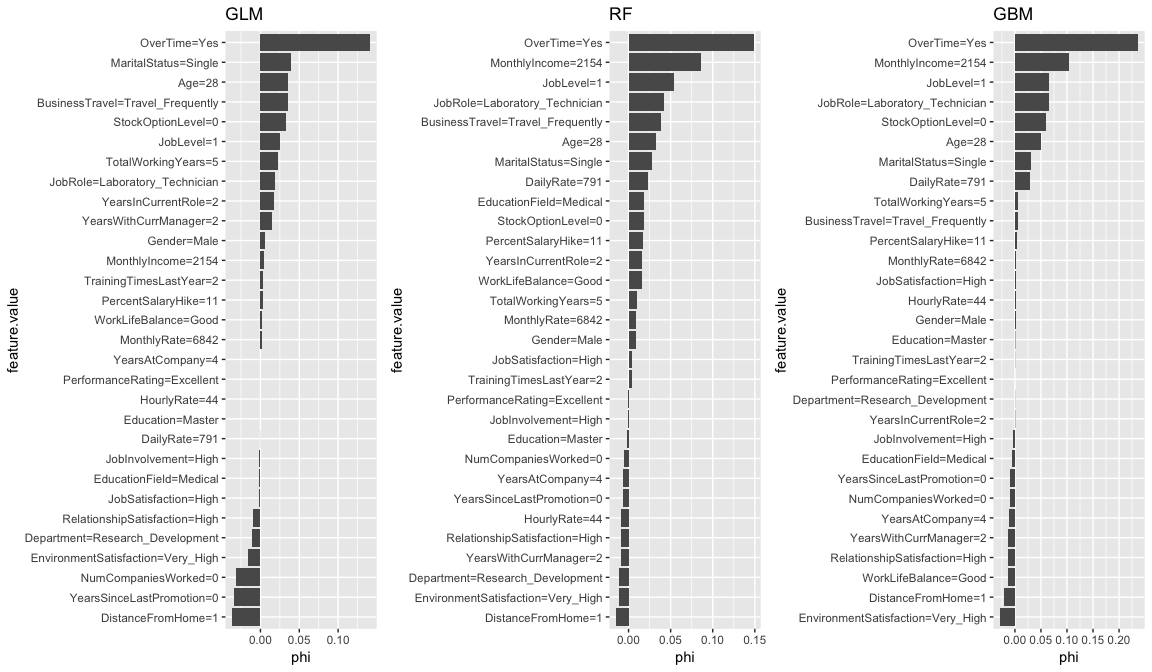
We can compare the Shapley values across each model to see if common themes appear. Again, OverTime is a common theme across all three models. We also see MonthlyIncome influential for the tree-based methods and there are other commonalities for the mildly influential variables across all three models (i.e. StockOptionLevel, JobLevel, Age, MaritalStatus).
shapley.glm <- Shapley$new(predictor.glm, x.interest = high_prob_ob) %>% plot() + ggtitle("GLM")
shapley.rf <- plot(shapley.rf) + ggtitle("RF")
shapley.gbm <- Shapley$new(predictor.gbm, x.interest = high_prob_ob) %>% plot() + ggtitle("GBM")
gridExtra::grid.arrange(shapley.glm, shapley.rf, shapley.gbm, nrow = 1)
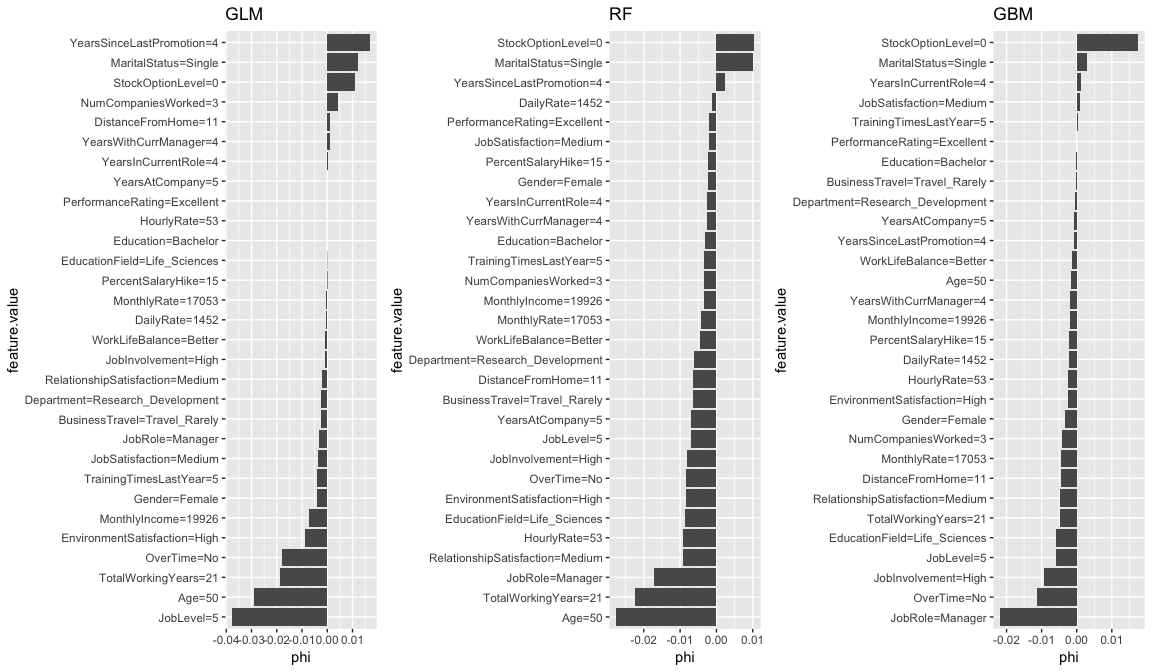
Similarly, we can apply for the low probability employee. Some common themes pop out for this employee as well. It appears that the age, total number of working years, and the senior position (JobLevel, JobRole) play a large part in the low predicted probability of attrition for this employee.
shapley.glm <- Shapley$new(predictor.glm, x.interest = low_prob_ob) %>% plot() + ggtitle("GLM")
shapley.rf <- Shapley$new(predictor.rf, x.interest = low_prob_ob) %>% plot() + ggtitle("RF")
shapley.gbm <- Shapley$new(predictor.gbm, x.interest = low_prob_ob) %>% plot() + ggtitle("GBM")
gridExtra::grid.arrange(shapley.glm, shapley.rf, shapley.gbm, nrow = 1)
Shapley values are considered more robust than the results you will get from LIME. However, similar to the different ways you can compute variable importance, although you will see differences between the two methods often you will see common variables being identified as highly influential in both approaches. Consequently, we should use these approaches to help indicate influential variables but not to definitively label a variables as the most influential.
iml is probably the most comprehensive package available for global and local model-agnostic interpretation. Although the interaction functions can become notably slow for wide data sets, the other functions are faster or comparable to existing packages (i.e. DALEX, pdp). I definitely recommend adding iml to your preferred ML toolkit. Check out the following to learn more about iml:
iml GitHub repo: Provides a short vignette but you can also dig into the codeiml) that describes the methodsThis tutorial was built with the following packages and R version. All code was executed on 2013 MacBook Pro with a 2.4 GHz Intel Core i5 processor, 8 GB of memory, 1600MHz speed, and double data rate synchronous dynamic random access memory (DDR3).
# packages used
pkgs <- c(
"rsample",
"dplyr",
"ggplot2",
"h2o",
"iml"
)
# package & session info
devtools::session_info(pkgs)
## setting value
## version R version 3.5.1 (2018-07-02)
## system x86_64, darwin15.6.0
## ui X11
## language (EN)
## collate en_US.UTF-8
## tz America/New_York
## date 2018-08-01
##
## package * version date source
## abind 1.4-5 2016-07-21 CRAN (R 3.5.0)
## assertthat 0.2.0 2017-04-11 CRAN (R 3.5.0)
## backports 1.1.2 2017-12-13 CRAN (R 3.5.0)
## BH 1.66.0-1 2018-02-13 CRAN (R 3.5.0)
## bindr 0.1.1 2018-03-13 CRAN (R 3.5.0)
## bindrcpp * 0.2.2 2018-03-29 CRAN (R 3.5.0)
## bitops 1.0-6 2013-08-17 CRAN (R 3.5.0)
## broom * 0.5.0 2018-07-17 CRAN (R 3.5.0)
## checkmate 1.8.5 2017-10-24 CRAN (R 3.5.0)
## class 7.3-14 2015-08-30 CRAN (R 3.5.1)
## cli 1.0.0 2017-11-05 CRAN (R 3.5.0)
## codetools 0.2-15 2016-10-05 CRAN (R 3.5.1)
## colorspace 1.3-2 2016-12-14 CRAN (R 3.5.0)
## crayon 1.3.4 2017-09-16 CRAN (R 3.5.0)
## CVST 0.2-2 2018-05-26 CRAN (R 3.5.0)
## data.table 1.11.4 2018-05-27 CRAN (R 3.5.0)
## ddalpha 1.3.3 2018-04-30 CRAN (R 3.5.0)
## DEoptimR 1.0-8 2016-11-19 CRAN (R 3.5.0)
## dichromat 2.0-0 2013-01-24 CRAN (R 3.5.0)
## digest 0.6.15 2018-01-28 CRAN (R 3.5.0)
## dimRed 0.1.0 2017-05-04 CRAN (R 3.5.0)
## dplyr * 0.7.6 2018-06-29 cran (@0.7.6)
## DRR 0.0.3 2018-01-06 CRAN (R 3.5.0)
## fansi 0.2.3 2018-05-06 cran (@0.2.3)
## foreach * 1.4.4 2017-12-12 CRAN (R 3.5.0)
## Formula 1.2-3 2018-05-03 CRAN (R 3.5.0)
## geometry 0.3-6 2015-09-09 CRAN (R 3.5.0)
## ggplot2 * 3.0.0 2018-07-03 CRAN (R 3.5.0)
## glmnet * 2.0-16 2018-04-02 CRAN (R 3.5.0)
## glue 1.3.0 2018-07-23 Github (tidyverse/glue@66de125)
## gower * 0.1.2 2017-02-23 CRAN (R 3.5.0)
## graphics * 3.5.1 2018-07-05 local
## grDevices * 3.5.1 2018-07-05 local
## grid 3.5.1 2018-07-05 local
## gtable 0.2.0 2016-02-26 CRAN (R 3.5.0)
## h2o * 3.18.0.11 2018-05-24 CRAN (R 3.5.0)
## iml * 0.5.1 2018-05-15 CRAN (R 3.5.0)
## inum 1.0-0 2017-12-12 CRAN (R 3.5.0)
## ipred 0.9-6 2017-03-01 CRAN (R 3.5.0)
## iterators 1.0.9 2017-12-12 CRAN (R 3.5.0)
## jsonlite 1.5 2017-06-01 CRAN (R 3.5.0)
## kernlab 0.9-26 2018-04-30 CRAN (R 3.5.0)
## KernSmooth 2.23-15 2015-06-29 CRAN (R 3.5.1)
## labeling 0.3 2014-08-23 CRAN (R 3.5.0)
## lattice 0.20-35 2017-03-25 CRAN (R 3.5.1)
## lava 1.6.1 2018-03-28 CRAN (R 3.5.0)
## lazyeval 0.2.1 2017-10-29 CRAN (R 3.5.0)
## libcoin 1.0-1 2017-12-13 CRAN (R 3.5.0)
## lubridate 1.7.4 2018-04-11 CRAN (R 3.5.0)
## magic 1.5-8 2018-01-26 CRAN (R 3.5.0)
## magrittr 1.5 2014-11-22 CRAN (R 3.5.0)
## MASS 7.3-50 2018-04-30 CRAN (R 3.5.1)
## Matrix * 1.2-14 2018-04-13 CRAN (R 3.5.1)
## methods * 3.5.1 2018-07-05 local
## Metrics 0.1.4 2018-07-09 CRAN (R 3.5.0)
## mgcv 1.8-24 2018-06-23 CRAN (R 3.5.1)
## munsell 0.4.3 2016-02-13 CRAN (R 3.5.0)
## mvtnorm 1.0-8 2018-05-31 CRAN (R 3.5.0)
## nlme 3.1-137 2018-04-07 CRAN (R 3.5.1)
## nnet 7.3-12 2016-02-02 CRAN (R 3.5.1)
## numDeriv 2016.8-1 2016-08-27 CRAN (R 3.5.0)
## partykit 1.2-2 2018-06-05 CRAN (R 3.5.0)
## pillar 1.3.0 2018-07-14 cran (@1.3.0)
## pkgconfig 2.0.1 2017-03-21 CRAN (R 3.5.0)
## plogr 0.2.0 2018-03-25 CRAN (R 3.5.0)
## plyr 1.8.4 2016-06-08 CRAN (R 3.5.0)
## prodlim 2018.04.18 2018-04-18 CRAN (R 3.5.0)
## purrr 0.2.5 2018-05-29 CRAN (R 3.5.0)
## R6 2.2.2 2017-06-17 CRAN (R 3.5.0)
## RColorBrewer 1.1-2 2014-12-07 CRAN (R 3.5.0)
## Rcpp 0.12.17 2018-05-18 CRAN (R 3.5.0)
## RcppRoll 0.2.2 2015-04-05 CRAN (R 3.5.0)
## RCurl 1.95-4.10 2018-01-04 CRAN (R 3.5.0)
## recipes 0.1.2 2018-01-11 CRAN (R 3.5.0)
## reshape2 1.4.3 2017-12-11 CRAN (R 3.5.0)
## rlang 0.2.1 2018-05-30 CRAN (R 3.5.0)
## robustbase 0.93-0 2018-04-24 CRAN (R 3.5.0)
## rpart 4.1-13 2018-02-23 CRAN (R 3.5.1)
## rsample * 0.0.2 2017-11-12 CRAN (R 3.5.0)
## scales 0.5.0 2017-08-24 CRAN (R 3.5.0)
## sfsmisc 1.1-2 2018-03-05 CRAN (R 3.5.0)
## splines 3.5.1 2018-07-05 local
## SQUAREM 2017.10-1 2017-10-07 CRAN (R 3.5.0)
## stats * 3.5.1 2018-07-05 local
## stringi 1.2.4 2018-07-20 cran (@1.2.4)
## stringr 1.3.1 2018-05-10 CRAN (R 3.5.0)
## survival 2.42-3 2018-04-16 CRAN (R 3.5.1)
## tibble 1.4.2 2018-01-22 CRAN (R 3.5.0)
## tidyr * 0.8.1 2018-05-18 CRAN (R 3.5.0)
## tidyselect 0.2.4 2018-02-26 CRAN (R 3.5.0)
## timeDate 3043.102 2018-02-21 CRAN (R 3.5.0)
## tools 3.5.1 2018-07-05 local
## utf8 1.1.4 2018-05-24 CRAN (R 3.5.0)
## utils * 3.5.1 2018-07-05 local
## viridisLite 0.3.0 2018-02-01 CRAN (R 3.5.0)
## withr 2.1.2 2018-03-15 CRAN (R 3.5.0)