07 Apr 2017

Although R provides built-in plotting functions, ggplot2 has become the preeminent visualization package in R. ggplot2 implements the Grammar of Graphics theory making it particularly effective for constructing visual representations of data and learning this library will allow you to make nearly any kind of (static) data visualization, customized to your exact specifications. This intro tutorial will get you started in making effective visualizations with R.
17 Mar 2017
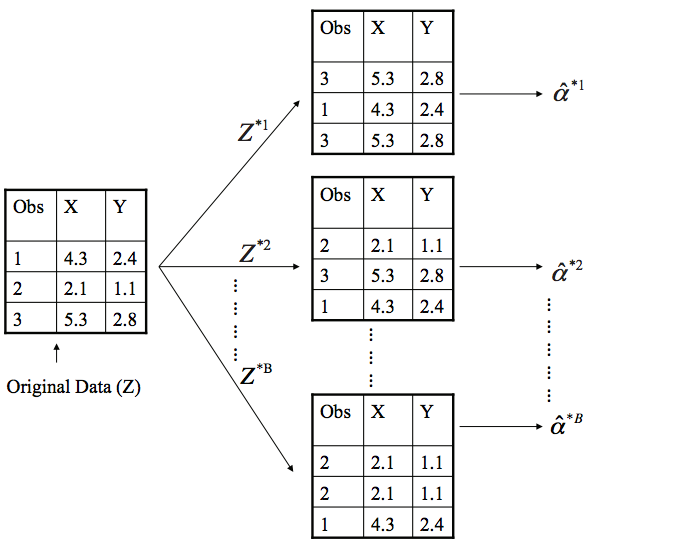
See the new tutorial on resampling methods, which are an indispensable tool in modern statistics. They involve repeatedly drawing samples from a training set and refitting a model of interest on each sample in order to obtain additional information about the fitted model. For example, in order to estimate the variability of a linear regression fit, we can repeatedly draw different samples from the training data, fit a linear regression to each new sample, and then examine the extent to which the resulting fits differ. Such an approach may allow us to obtain information that would not be available from fitting the model only once using the original training sample.
03 Mar 2017
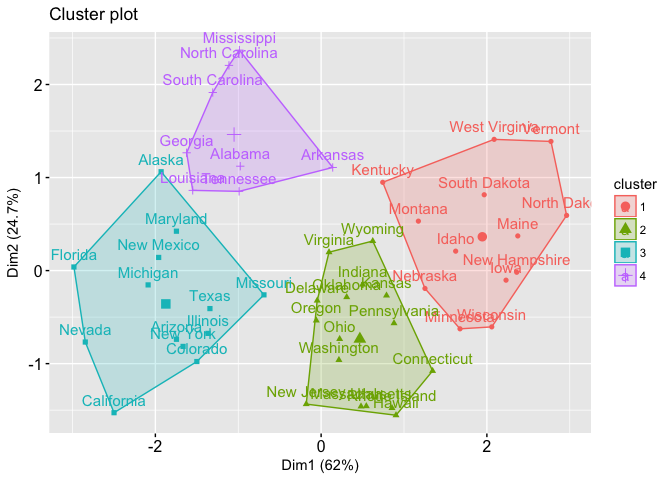
Clustering is a broad set of techniques for finding subgroups of observations within a data set. When we cluster observations, we want observations in the same group to be similar and observations in different groups to be dissimilar. Clustering allows us to identify which observations (i.e. customers, students, states) are alike, and potentially categorize them therein. Check out our new tutorials covering k-means and hierarchical clustering.
17 Feb 2017
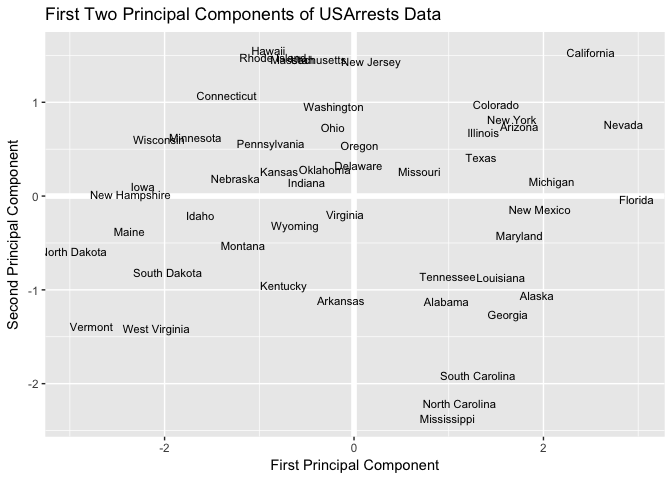
Principal components analysis (PCA) reduces the dimensionality of our data, allowing most of the variability to be explained using fewer variables than the original data set. This allows us to understand the primary features that can best represent our data. Check out the latest tutorial which covers PCA
03 Feb 2017
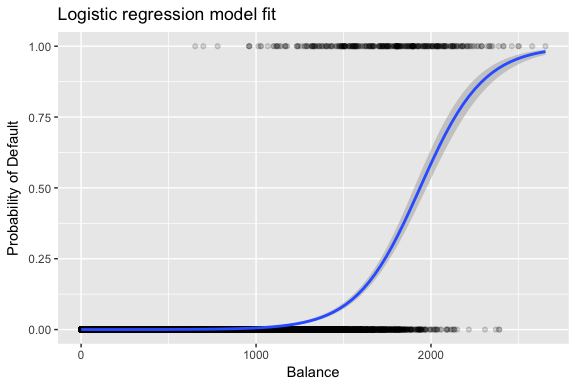
Logistic regression is a foundational analytic technique for classification problems. It allows us to estimate the probability of a categorical response based on one or more predictor variables and tells us if the presence of a predictor increases (or decreases) the probability of a given outcome by a specific percentage. Check out the recently added tutorial on logistic regression.